Scaling Forward Gradient With Local Losses
Abstract
Forward gradient learning computes a noisy directional gradient and is a biologically plausible alternative to backprop for learning deep neural networks. However, the standard forward gradient algorithm, when applied naively, suffers from high variance when the number of parameters to be learned is large. In this paper, we propose a series of architectural and algorithmic modifications that together make forward gradient learning practical for standard deep learning benchmark tasks. We show that it is possible to substantially reduce the variance of the forward gradient estimator by applying perturbations to activations rather than weights. We further improve the scalability of forward gradient by introducing a large number of local greedy loss functions, each of which involves only a small number of learnable parameters, and a new MLPMixer-inspired architecture, LocalMixer, that is more suitable for local learning. Our approach matches backprop on MNIST and CIFAR-10 and significantly outperforms previously proposed backprop-free algorithms on ImageNet. Code is released at https://github.com/google-research/google-research/tree/master/local_forward_gradient.
1 Introduction
Most deep neural networks today are trained using the backpropagation algorithm (a.k.a. backprop) (Werbos, 1974; LeCun, 1985; Rumelhart et al., 1986), which efficiently computes the gradients of the weight parameters by propagating the error signal backwards from the loss function to each layer. Although artificial neural networks were originally inspired by biological neurons, backprop has always been considered as “biologically implausible” as the brain does not form symmetric backward connections or perform synchronized computations. From an engineering perspective, backprop is incompatible with a massive level of model parallelism, and restricts potential hardware designs. These concerns call for a drastically different learning algorithm for deep networks.
In the past, there have been attempts to address the above weight transport problem by introducing random backward weights (Lillicrap et al., 2016; Nøkland, 2016), but they have been found to scale poorly on larger datasets such as ImageNet (Bartunov et al., 2018). Addressing the issue of global synchronization, several papers showed that greedy local loss functions can be almost as good as end-to-end learning (Belilovsky et al., 2019; Löwe et al., 2019; Xiong et al., 2020). However, they still rely on backprop for learning a number of internal layers within each local module.
Approaches based on weight perturbation, on the other hand, directly send the loss signal back to the weight connections and hence do not require any backward weights. In the forward pass, the network adds a slight perturbation to the synaptic connections and the weight update is then multiplied by the negative change in the loss. Weight perturbation was previously proposed as a biologically plausible alternative to backprop (Xie and Seung, 1999; Seung, 2003; Fiete and Seung, 2006). Instead of directly perturbing the weights, it is also possible to use forward-mode automatic differentiation (AD) to compute a directional gradient of the final loss along the perturbation direction (Pearlmutter, 1994). Algorithms based on forward-mode AD have recently received renewed interest in the context of deep learning (Baydin et al., 2022; Silver et al., 2022). However, existing approaches suffer from the curse of dimensionality, and the variance of the estimated gradients is too high to effectively train large networks.
In this paper, we revisit activity perturbation (Le Cun et al., 1988; Widrow and Lehr, 1990; Fiete and Seung, 2006) as an alternative to weight perturbation. As previous works focused on specific settings, we explore the general applicability to large networks trained on challenging vision tasks. We prove that activity perturbation yields lower-variance gradient estimates than weight perturbation, and provide a continuous-time rate-based interpretation of our algorithm. We directly address the scalability issue of forward gradient learning by designing an architecture with many local greedy loss functions, isolating the network into local modules and hence reducing the number of learnable parameters per loss. Unlike prior work that only adds local losses along the depth dimension, we found that having patch-wise and channel group-wise losses is also critical. Lastly, inspired by the design of MLPMixer (Tolstikhin et al., 2021), we designed a network called LocalMixer, featuring a linear token mixing layer and grouped channels for better compatibility with local learning.
We evaluate our local greedy forward gradient algorithm on supervised and self-supervised image classification problems. On MNIST and CIFAR-10, our learning algorithm performs comparably with backprop, and on ImageNet, it performs significantly better than other biologically plausible alternatives using asymmetric forward and backward weights. Although we have not fully matched backprop on larger-scale problems, we believe that local loss design could be a critical ingredient for biologically plausible learning algorithms and the next generation of model-parallel computation.
2 Related Work
Ever since the perceptron era, the design of learning algorithms for neural networks, especially algorithms that could be realized by biological brains, has been a central interest. Review papers by Whittington and Bogacz (2019) and Lillicrap et al. (2020) have systematically summarized the progress of biologically plausible deep learning. Here, we discuss related work in the following subtopics.
Forward gradient and reinforcement learning.
Our work leverages forward-mode automatic differentiation (AD), which was first proposed by Wengert (1964). Later it was used to learn recurrent neural networks (Williams and Zipser, 1989) and to compute Hessian vector products (Pearlmutter, 1994). Computing the true gradient using forward-mode AD requires the full Jacobian, which is often large and expensive to compute. Recently, Baydin et al. (2022) and Silver et al. (2022) proposed to update the weights based on the directional gradient along a random or learned perturbation direction. They found that this approach is sufficient for small-scale problems. This general family of algorithms is also related to reinforcement learning (RL) and evolution strategies (ES), since in each case the network receives a global reward. RL and ES have a long history of application in neural networks (Whitley, 1993; Stanley and Miikkulainen, 2002; Salimans et al., 2017), and they are effective for certain continuous control and decision-making tasks. Clark et al. (2021) found global credit assignment can also work well in vector neural networks where weights are only present between vectorized groups of neurons.
Greedy local learning.
There have been numerous attempts to use local greedy learning objectives for training deep neural networks. Greedy layerwise pretraining (Bengio et al., 2006; Hinton et al., 2006; Vincent et al., 2010) trains individual layers or modules one at a time to greedily optimize an objective. Local losses are typically applied to different layers or residual stages, using common supervised and self-supervised loss formulations (Belilovsky et al., 2019; Nøkland and Eidnes, 2019; Löwe et al., 2019; Belilovsky et al., 2020). Xiong et al. (2020); Gomez et al. (2020) proposed to use overlapped losses to reduce the impact of greedy learning. Patel et al. (2022) proposed to split a network into neuron groups. Laskin et al. (2020) applied greedy local learning on model parallelism training, and Wang et al. (2021) proposed to add a local reconstruction loss for preserving information. However, most local learning approaches proposed in the last decade rely on backprop to compute the weight updates within a local module. One exception is the work of Nøkland and Eidnes (2019), which avoided backprop by using layerwise objectives coupled with a similarity loss or a feedback alignment mechanism. Gated linear networks and their variants (Veness et al., 2017, 2021; Sezener et al., 2021) ask every neuron to make a prediction, and have shown interesting results on avoiding catastrophic forgetting. From a theoretical perspective, Baldi and Sadowski (2016) provided insights and proofs on why local learning can be worse than global learning.
Asymmetric feedback weights.
Backprop relies on weight symmetry: the backward weights are the same as the forward weights. Past research has looked at whether this constraint is necessary. Lillicrap et al. (2016) proposed feedback alignment (FA) that uses random and fixed backward weights and found it can support error driven learning in neural networks. Direct FA (Nøkland, 2016) uses a single backward layer to wire the loss function back to each layer. There have also been methods that aim to explicitly update backward weights. Recirculation (Hinton and McClelland, 1987) and target propagation (TP) (Bengio, 2014; Lee et al., 2015; Bartunov et al., 2018) use local reconstruction objective to learn separate forward and backward weights as approximate inverses of each other. Ladder networks (Rasmus et al., 2015) found local reconstruction objectives and asymmetric weights can help achieve strong semi-supervised learning performance. However, Bartunov et al. (2018) reported both FA and TP algorithms do not scale to larger problems such as ImageNet, where their error rates are over 90%. Liao et al. (2016); Xiao et al. (2019) proposed sign symmetry (SS) where each backward connection weight share the same sign as the forward counterpart. Akrout et al. (2019) proposed weight mirroring and the modified Kolen-Pollack algorithm (Kolen and Pollack, 1994) to align forward and backward weights. Woo et al. (2021) proposed to update using activities from several layers below to avoid bidirectional connections. Compared to these works, we circumvent the issue of weight symmetry, and more generally network symmetry, by using only reward (and the change rate thereof), instead of backward weights.
Biologically plausible perturbation learning.
Forward gradient is related to perturbation learning in the biology context. Traditionally, neural plasticity learning rules focus on deriving weight updates as a function of the input and output activity of a neuron (Hebb, 1949; Widrow and Hoff, 1960; Oja, 1982; Bienenstock et al., 1982; Abbott and Nelson, 2000). Weight perturbation learning (Jabri and Flower, 1992), on the other hand, is much more general as it permits any form of global reward (Schultz et al., 1997). It was developed in both rated-based and spiking-based formuations (Xie and Seung, 1999; Seung, 2003). Activity (or node) perturbation was proposed in shallow networks (Le Cun et al., 1988; Widrow and Lehr, 1990) and later in a spike-based continuous time network (Fiete and Seung, 2006), where it was interpreted as the perturbation of the conductance of neurons. Werfel et al. (2003) showed that backprop has a faster convergence rate than perturbation learning, and activity perturbation wins over weight perturbation by another factor. In our work, we show activity perturbation has lower gradient estimation variance compared to weight perturbation.
3 Forward Gradient Learning
In this section, we review and establish the technical background for our learning algorithm. We first review the technique of forward-mode automatic differentiation (AD). Second, we formulate two different types of perturbation in the weight space or activity space.
3.1 Forward-mode automatic differentiation (AD)
Let . The Jacobian of , , is a matrix of size . Forward-mode AD computes the matrix-vector product , where . It is defined as the directional gradient along evaluated at :
| (1) |
For comparison, backprop, also known as reverse-mode AD, computes the vector-Jacobian product , where , which corresponds to the last term in the chain rule. In contrast to reverse-mode AD, forward-mode AD only requires one forward pass, which is augmented with the derivative information. To compute the Jacobian vector product of a node in a computation graph, first the input node will be augmented with , which is the vector to be multiplied. Then for other nodes, we send in a tuple of as inputs and compute a tuple as outputs, where and are the intermediate derivatives at node and node , i.e. , and is the Jacobian between and . In the JAX library (Bradbury et al., 2018), forward-mode AD is implemented as jax.jvp.
3.2 Weight-perturbed forward gradient
Weight perturbation to generate weight updates was originally explored in (Barto et al., 1983; Xie and Seung, 1999; Seung, 2003). Baydin et al. (2022) uses the technique of forward-mode AD to implement weight perturbation, which is better than finite differences in terms of numerical stability. Let be the weight connection between unit and , and be the loss function. We can estimate the gradient by sampling a random matrix with iid elements drawn from a zero-mean unit-variance Gaussian distribution. The estimator is
| (2) |
Intuitively, this estimator samples a random perturbation direction and tests how it aligns with the true gradient by using forward-mode to perform the dot product, and then multiplies the scalar alignment with the perturbation direction again. Baydin et al. (2022) referred this form of gradient estimation using forward-mode AD as “forward gradient”. To distinguish with another form of perturbation we detail later, we refer this to as “weight-perturbed forward gradient”, or simply as “weight perturbation”.
3.3 Activity-perturbed forward gradient
An alternative to perturbing the weights is to instead perturb the activities, which can reduce the number of perturbation dimensions per example. Activity perturbation was originally explored in Le Cun et al. (1988); Widrow and Lehr (1990) under restrictive assumptions. Here, we introduce a general way to estimate gradients using activity perturbation. It is potentially biologically plausible, since it could correspond to perturbation of the conductance in each neuron (Fiete and Seung, 2006). Here, we focus on a discrete-time rate-based formulation for simplicity. Let denote the activity of the -th pre-synaptic neuron and denote that of the -th post-synaptic neuron before the non-linear activation function, and be the perturbation of . The activity-perturbed forward gradient estimator is
| (3) |
where the inner product between and is again computed by using forward-mode AD.
3.4 Theoretical properties
In this section we aim to analyze the expectation and variance properties of forward gradient estimators. We focus our analysis on the gradient of one weight matrix , but the conclusion holds for a network with many weight matrices too.
| Unbiased? | Avg. Variance (shared) | Avg. Variance (independent) | |
|---|---|---|---|
| Yes | |||
| Yes |
Table 1 summarizes the theoretical results111All proofs can be found in Appendix 8 and 9. Numerical simulation results can be found in Appendix 10.. With a batch size of , independent perturbation can achieve reduction of variance, whereas shared perturbation has a constant variance term dominated by the squared gradient norm. However, when performing independent weight perturbation, matrix multiplications cannot be batched because each example’s activation vector is multiplied with a different weight matrix. By contrast, independent activity perturbation admits batched matrix multiplications. Moreover, activity perturbation enjoys a factor of fan-in () times smaller variance compared to weight perturbation since the number of perturbed elements is the number of output units instead of the size of the whole weight matrix. The only drawback of activity perturbation is the memory required for storage of intermediate activations, in exchange for a factor of reduction in variance. However, for both activity and weight perturbation, the variance still grows with larger networks. In Section 4 we will further reduce the variance by introducing local loss functions.
3.5 Continuous-time rate-based models
Forward-mode AD can be viewed as computing the first-order time derivative in a continuous-time physical system. Suppose the tuples passed between nodes of the computation graph are , where is the change in over time. The computation is then the same as forward-mode AD. For each node, , where is the Jacobian between the output and the input. Note that in a physical system we don’t have to explicitly perform the differentiation operation by running two forward passes. Instead the first-order derivative information is readily available in the analog signal, and we only need to plug the output signal into a differentiator circuit.
The activity-perturbed learning rule for a continuous time system is thus , where is the pre-synaptic activity, and is the rate of change in the post-synaptic activity, which is the perturbation direction for a small period of time, and is the rate of change of reward (or the negative loss). The reward controls whether learning is Hebbian or anti-Hebbian. Both Hinton and others (2007) and Bengio et al. (2017) propose to use a product of pre-synaptic activity and the rate of change of postsynaptic activity. However, they did not consider using the rate of change of reward as a modulator and instead relied on another set of feedback weights to communicate the error signal through inputs. In contrast, we show that by broadcasting the rate of change of reward, we can actually bypass the weight transport problem.
3.6 Activation sparsity and normalization functions
In networks with ReLU activations, we can leverage ReLU sparsity to achieve further variance reduction, because the inactivated units will have zero gradient and therefore we should not perturb these units, and set the perturbation to be zero.
Normalization layers are often added in deep neural networks after the linear layer. To compute the correct gradient in activity perturbation, we also need to account for normalization in the weight update rule. Since there is no backward weight connections, one option is to simply apply backprop on normalization layers. However, we also found that it is also fine to ignore the gradient of normalization layer when using layer normalization.
4 Scaling with Local Losses
As we have explained in the previous section, perturbation learning can suffer from a curse of dimensionality: the variance grows with the number of perturbation dimensions, and in deep networks there are often millions of parameters changing at the same time. One way to limit the number of learnable dimensions is to divide the network into submodules, each with a separate loss function. In this section, we will explore several ways to increase the number of local losses to tame the variance.

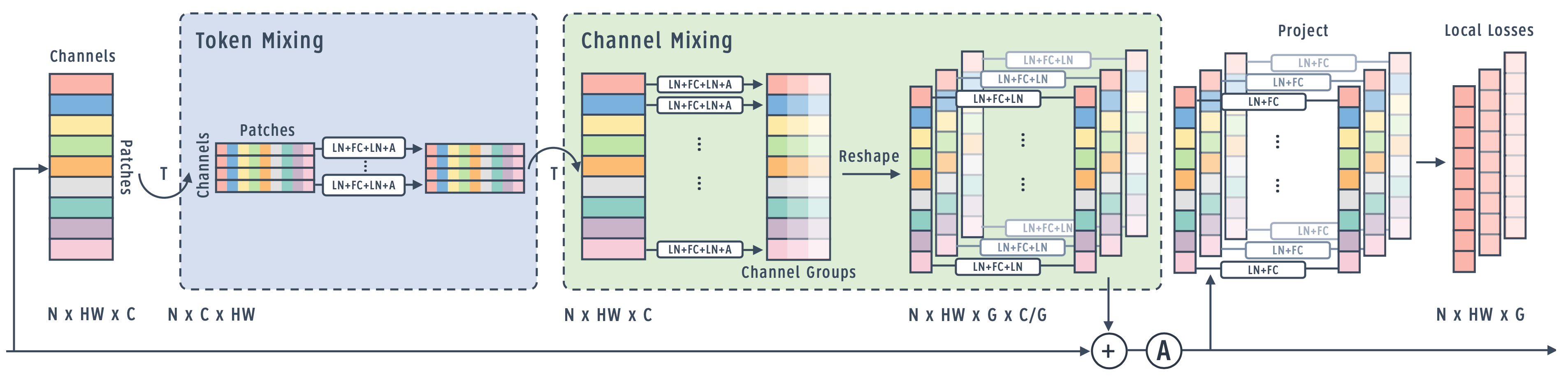
1) Blockwise loss.
First, we will divide the network into modules in depth. Each module consists of several layers. At the end of each module, we compute a loss function, and that loss is used to update the parameters in that module. This approach is equivalent of adding a “stop gradient” operator in between modules. Such local greedy losses were previously explored in Belilovsky et al. (2019) and Löwe et al. (2019).
2) Patchwise loss.
Sensory input signals such as images have spatial dimensions. We will apply a separate loss patchwise along these spatial dimensions. In the Vision Transformer architecture (Vaswani et al., 2017; Dosovitskiy et al., 2021), each spatial token represents a patch in the image. In modern deep networks, parameters in each spatial location are often shared to improve data efficiency and reduce memory bandwidth utilization. Although naive weight sharing is not biologically plausible, we still consider shared weights in this work. It may be possible to mimic the effect of weight sharing by adding knowledge distillation (Hinton et al., 2015) losses in between patches.
3) Groupwise loss.
Lastly, we turn to the channel dimension. To create multiple losses, we split the channels into a number of groups, and each group is attached to a loss function (Patel et al., 2022). To prevent groups from communicating between each other, channels are only connected to other channels within the same group. A grouped linear layer is computed as for individual group . Whereas previous work used channel groups to improve computational efficiency (Krizhevsky et al., 2012; Ioannou et al., 2017; Xie et al., 2017), in our work, adding groups contributes to the total number of losses and thus reduces variance.
Feature aggregators.
Naively applying losses separately to the spatial and channel dimensions leads to suboptimal performances, since each dimension contains only local information. For losses of standard tasks such as classification, the model needs a global view of the inputs to make a decision. Standard architectures obtain this global view by performing global average pooling layer before the final classification layer. We therefore explore strategies for aggregating information from other groups and spatial patches before the local loss function.
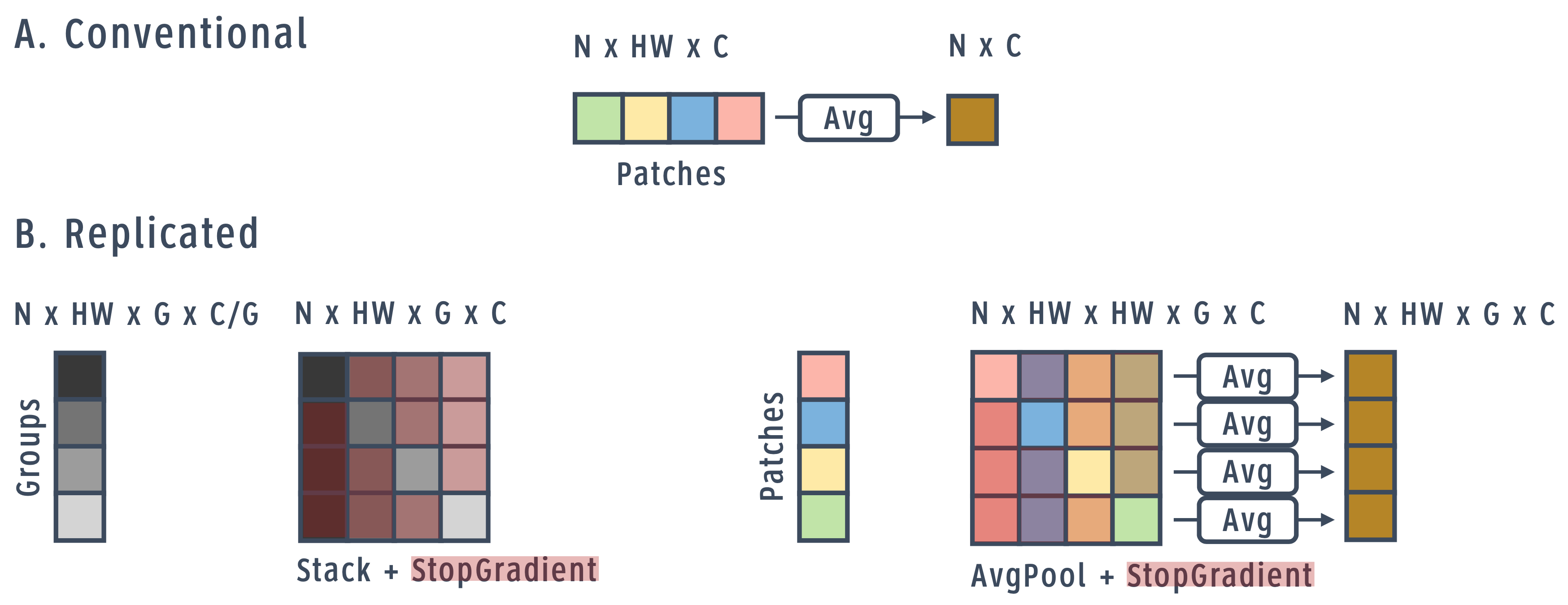
We would prefer to perform aggregation without reducing the total number of dimensions. We thus propose a replicated design for feature aggregation, shown in Figure 3. First, channel groups are copied and communicated to one another, but every group except the active group itself is masked with stop gradient so that other groups do not affect the forward gradient computation:
| (4) |
where and index the patches and groups respectively. Similarly, each spatial location is also copied, communicated, and masked, and then averaged locally:
| (5) |
The output of feature aggregation is the same as that of the conventional global average pooling layer. The difference is that here the loss is replicated and different patch groups are activated in each loss.
Learning objectives.
We consider the supervised classification loss and the contrastive InfoNCE loss (van den Oord et al., 2018; Chen et al., 2020), which are the two most commonly used losses in image representation learning. For supervised classification, we attach a shared linear layer (shared across ) on top of the aggregated features for a cross entropy loss: . The loss is of the same value across each group and patch location.
For contrastive learning, the linear layer becomes a linear feature projector. Suppose and are the two different views of the -th example, the InfoNCE loss for contrastive learning is:
| (6) |
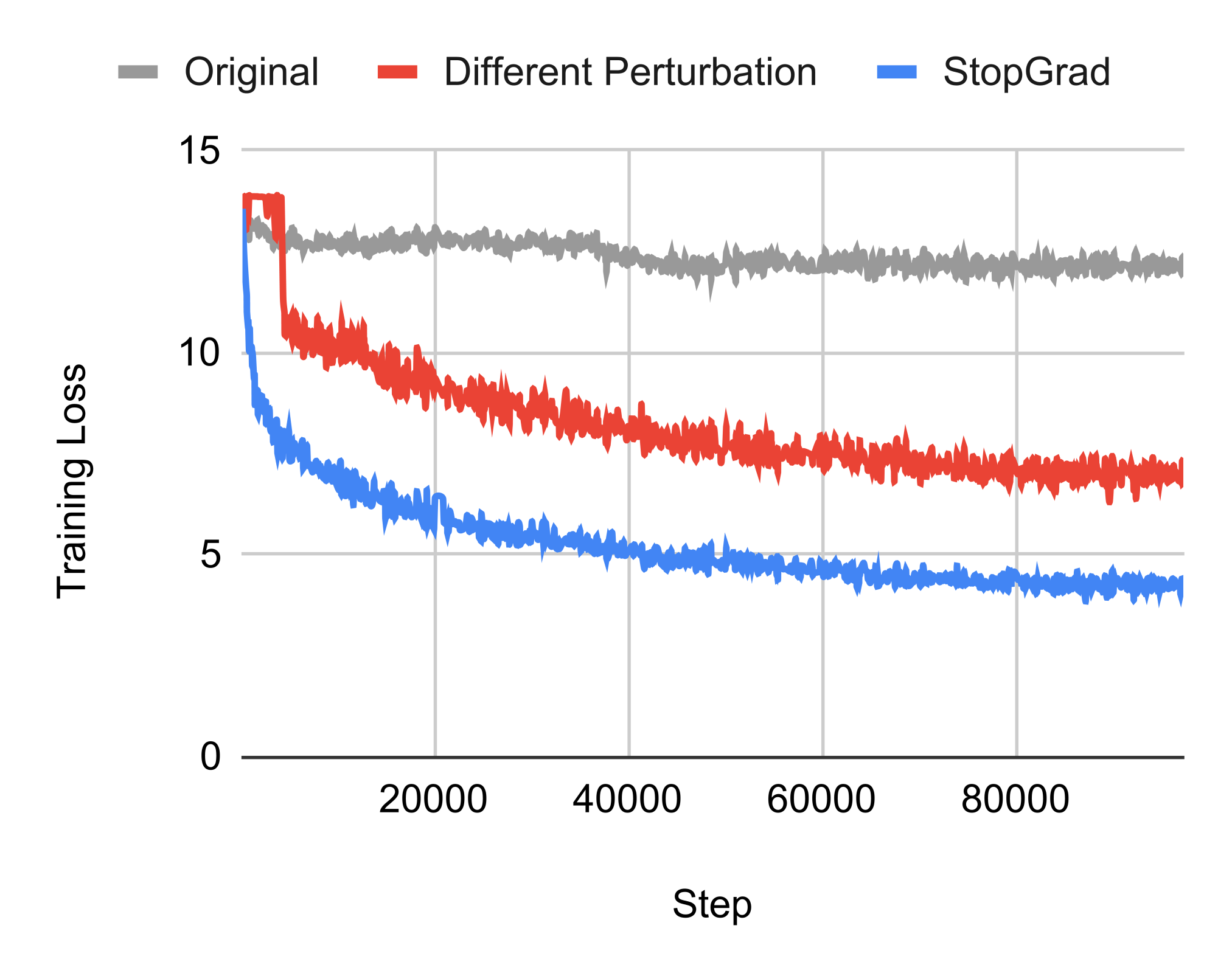
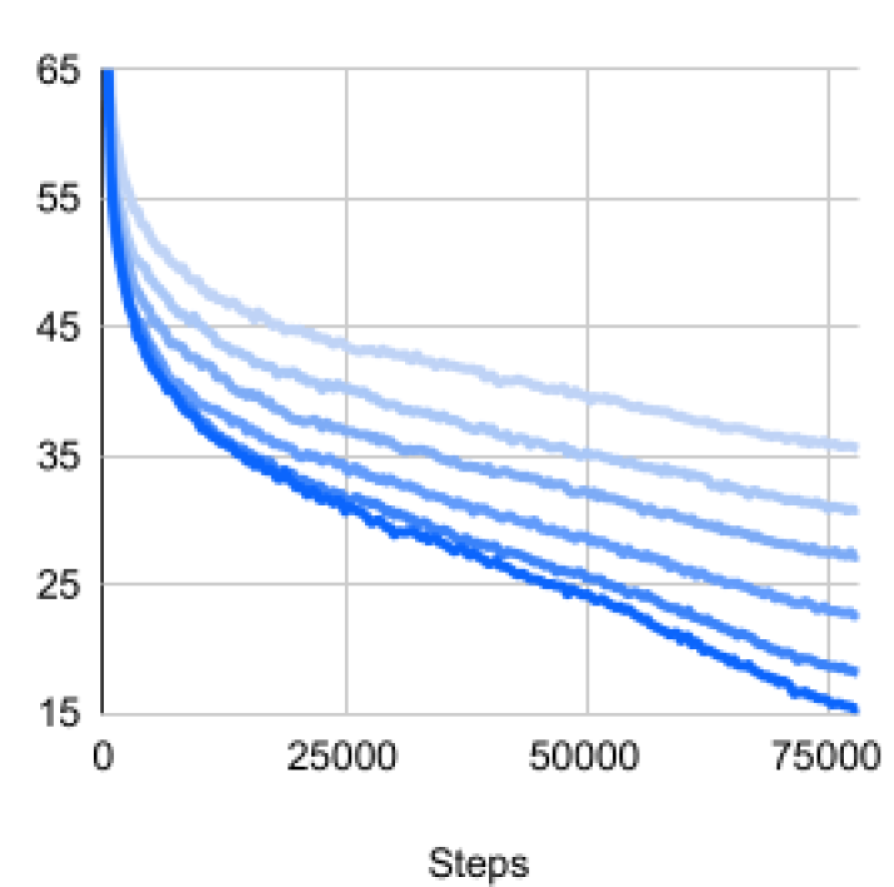
Note that we add a stop gradient operator on the second view. It is usually unnecessary to add this stop gradient in the InfoNCE loss; however, we found that perturbation-based methods require a stop gradient and otherwise the loss will not go down. This is likely because we share the perturbations on both views, and having the same perturbation will increase the dot product between the two views but is not desired from a representation learning perspective. Figure 4 shows a comparison of the loss curves. Non-shared perturbations also work but are worse than stop gradient.
5 Implementation
Network architecture.
We propose the LocalMixer architecture that is more suitable for local learning. It takes inspiration from MLPMixer (Tolstikhin et al., 2021), which consists of fully connected networks and residual blocks. We leverage the fully connected networks so that each spatial patch performs computations without interfering with other patches, which is more compatible with our local learning objective. An image is divided into non-overlapping patches (i.e. tokens), and each block consists of token and channel mixing layers. Figure 1 shows the high level architecture, and Figure 2 shows the detailed diagram for one residual block. We add a linear projector/classification layer to attach a loss function at the end of each block. The last layer always uses backprop to update weights. For token mixing layers, we use one linear fully connected layer instead of an MLP, since we would like to make each block as shallow as possible. Before the last channel mixing layer, features are reshaped into a number of groups, and the last layer is fully connected within each feature group. Table 2 shows architectural details for the different sizes of models we investigate.
| Type | Blocks | Patches | Channels | Groups | Params | Dataset |
|---|---|---|---|---|---|---|
| LocalMixer S/1/1 | 1 | 11 | 256 | 1 | 272K | MNIST |
| LocalMixer M/1/16 | 1 | 11 | 512 | 16 | 429K | MNIST |
| LocalMixer M/8/16 | 4 | 88 | 512 | 16 | 919K | CIFAR-10 |
| LocalMixer L/8/64 | 4 | 88 | 2048 | 64 | 13.1M | CIFAR-10 |
| LocalMixer L/32/64 | 4 | 3232 | 2048 | 64 | 17.3M | ImageNet |
Normalization.
There are many ways of performing normalization within a neural network across different tensor dimensions (Krizhevsky et al., 2012; Ioffe and Szegedy, 2015; Ba et al., 2016; Ren et al., 2017; Wu and He, 2018). We opted for a local variant of layer normalization that normalizes within each local spatial patch of features (Ren et al., 2017). For grouped linear layers, each group is normalized separately (Wu and He, 2018). Empirically, we found such local normalization performs better on contrastive learning experiments and about the same as layer normalization on supervised experiments. Local normalization is also more biologically plausible as it does not perform global communication. Conventionally, normalization layers are placed after linear layers. In MLPMixer (Tolstikhin et al., 2021), layer normalization is placed at the beginning of each residual block. We found it is the best to place normalization before and after each linear layer, as shown in Figure 2. Empirically this design choice does not make much difference for backprop, but it allows forward gradient learning to learn much faster and achieve lower training errors.
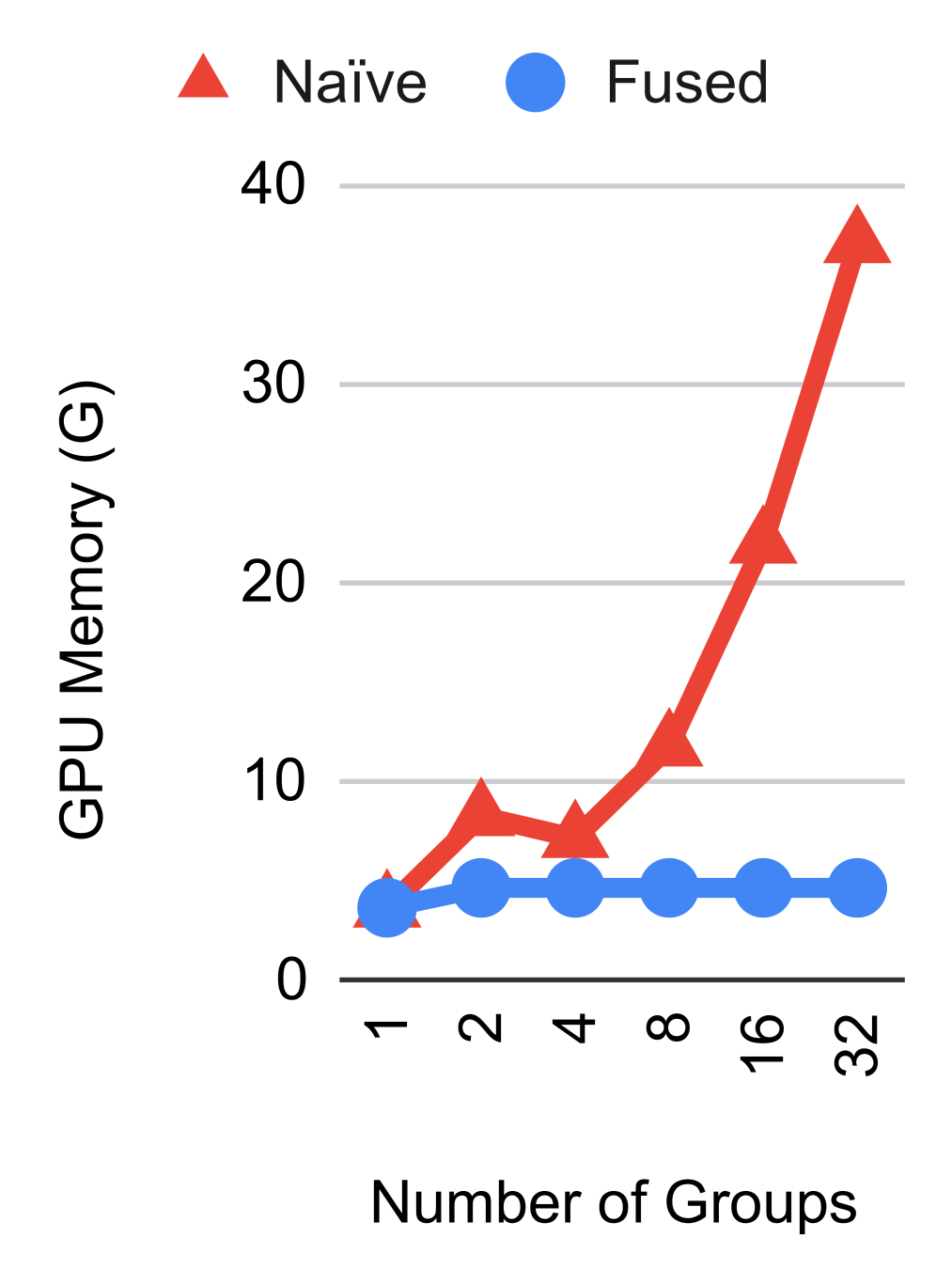
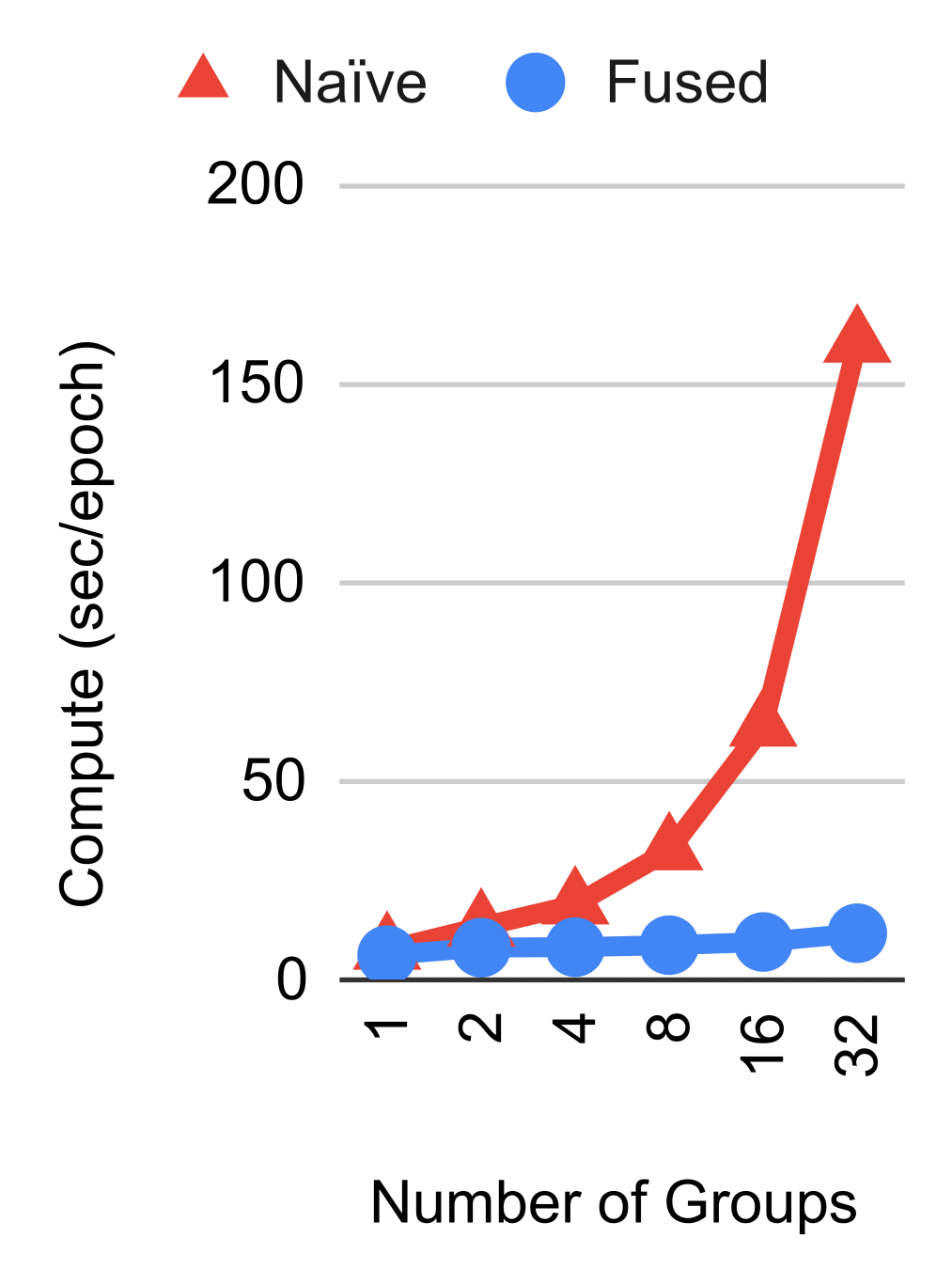
Efficient implementation of replicated losses.
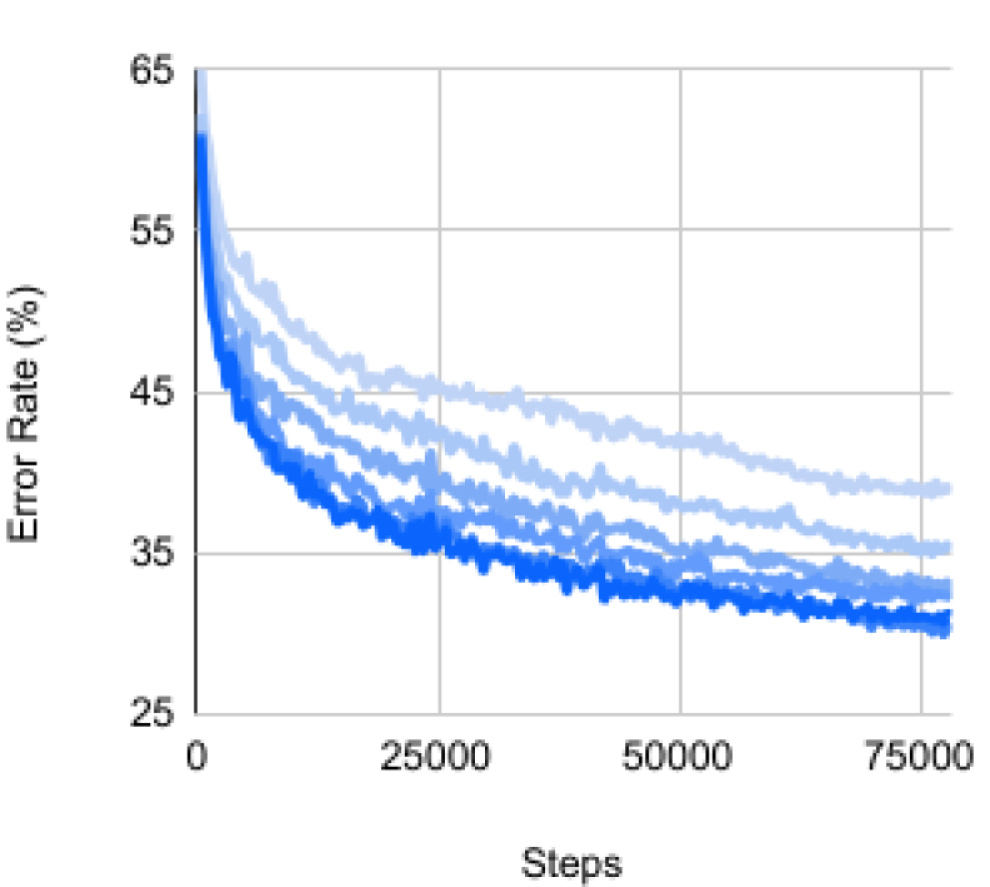
Due to the design of feature aggregation and replicated losses, a naïve implementation of groups can be very inefficient in terms of both memory consumption and compute. However, each spatial group actually computes the same aggregated feature and loss function. This means that it is possible to share most of the computation across loss functions when performing both backprop and forward gradient. We implemented our custom JAX JVP/VJP functions (Bradbury et al., 2018) and observed significant memory savings and compute speed-ups for replicated losses, which would otherwise not be feasible to run on modern hardware. The results are reported in Figure 5. A code snippet is included in Appendix 12.
6 Experiments
We compare our proposed algorithm to a set of alternatives: Backprop, Feedback Alignment and other global variants of Forward Gradient. Backprop is a biologically implausible oracle, since it computes true gradients whereas we compute noisy gradients. Feedback alignment computes approximate gradients by using a set of random backward weights. We explain each method below.
1) Backprop (BP).
We include the standard backprop algorithm as well as its local variants. Local Backprop (L-BP) adds local losses as proposed, but still permits gradient to flow in an end-to-end fashion. Local Greedy Backprop (LG-BP) in addition adds stop gradient operators in between blocks. This is to provide a comparison to our methods by computing true local gradients. LG-BP is similar in spirit to recent local learning algorithms (Belilovsky et al., 2019; Löwe et al., 2019).
2) Feedback Alignment (FA).
The standard FA algorithm (Lillicrap et al., 2016) adds a set of random and fixed backward weights. We assume that the gradients to normalization layers and activation functions are known since they do not have weight connections. Local Feedback Alignment (L-FA) adds local losses as proposed, but still permits error signals to flow back. Local Greedy Feedback Alignment (LG-FA) adds a stop gradient to prevent error signals from flowing back, similar to the backprop-free algorithm in Nøkland and Eidnes (2019).
| Dataset | MNIST | MNIST | CIFAR-10 | ImageNet |
|---|---|---|---|---|
| Network | S/1/1 | M/1/16 | M/8/16 | L/32/64 |
| Metric | Test / Train Err. (%) | Test / Train Err. (%) | Test / Train Err. (%) | Test / Train Err. (%) |
| BP | 2.66 / 0.00 | 2.41 / 0.00 | 33.62 / 0.00 | 36.82 / 14.69 |
| L-BP | 2.38 / 0.00 | 2.16 / 0.00 | 30.75 / 0.00 | 42.38 / 22.80 |
| LG-BP | 2.43 / 0.00 | 2.81 / 0.00 | 33.84 / 0.05 | 54.37 / 39.66 |
| BP-free algorithms | ||||
| FA | 2.82 / 0.00 | 2.90 / 0.00 | 39.94 / 28.44 | 94.55 / 94.13 |
| L-FA | 3.21 / 0.00 | 2.90 / 0.00 | 39.74 / 28.98 | 87.20 / 85.69 |
| LG-FA | 3.11 / 0.00 | 2.50 / 0.00 | 39.73 / 32.32 | 85.45 / 82.83 |
| DFA | 3.31 / 0.00 | 3.17 / 0.00 | 38.80 / 33.69 | 91.17 / 90.28 |
| FG-W | 9.25 / 8.93 | 8.56 / 8.64 | 55.95 / 54.28 | 97.71 / 97.58 |
| FG-A | 3.24 / 1.53 | 3.76 / 1.75 | 59.72 / 41.29 | 98.83 / 98.80 |
| LG-FG-W | 9.25 / 8.93 | 5.66 / 4.59 | 52.70 / 51.71 | 97.39 / 97.29 |
| LG-FG-A | 3.24 / 1.53 | 2.55 / 0.00 | 30.68 / 19.39 | 58.37 / 44.86 |
| Dataset | CIFAR-10 | CIFAR-10 | ImageNet |
|---|---|---|---|
| Network | M/8/16 | L/8/64 | L/32/64 |
| Metric | Test / Train Err. (%) | Test / Train Err. (%) | Test / Train Err. (%) |
| BP | 24.11 / 21.08 | 17.53 / 13.35 | 55.66 / 49.79 |
| L-BP | 24.69 / 21.80 | 19.13 / 13.60 | 59.11 / 52.50 |
| LG-BP | 29.63 / 25.60 | 23.62 / 16.80 | 68.36 / 62.53 |
| BP-free algorithms | |||
| FA | 45.87 / 44.06 | 67.93 / 65.32 | 82.86 / 80.21 |
| L-FA | 37.73 / 36.13 | 31.05 / 26.97 | 83.18 / 79.80 |
| LG-FA | 36.72 / 34.06 | 30.49 / 25.56 | 82.57 / 79.53 |
| DFA | 46.09 / 42.76 | 39.26 / 37.17 | 93.51 / 92.51 |
| FG-W | 53.37 / 51.56 | 50.45 / 45.64 | 91.94 / 89.69 |
| FG-A | 54.59 / 52.96 | 56.63 / 56.09 | 97.83 / 97.79 |
| LG-FG-W | 52.66 / 50.23 | 52.27 / 48.67 | 91.36 / 88.81 |
| LG-FG-A | 32.88 / 29.73 | 26.81 / 23.90 | 73.24 / 66.89 |
3) Forward Gradient (FG).
This family of methods comprises our proposed algorithm and related approaches. Weight-perturbed forward gradient (FG-W) was proposed by Baydin et al. (2022). In this paper, we propose the activity perturbation variant (FG-A). We further add local objective functions, producing LG-FG-W and LG-FG-A, which stand for Local Greedy Forward Gradient Weight/Activity-Perturbed. For local perturbation to work, we have to add a stop gradient in between blocks so each perturbation has a single corresponding loss. We expect LG-FG-A to achieve the best performance among other variants because it can leverage the variance reduction benefit from both activity perturbation and local losses.
Datasets.
We use standard image classification datasets to benchmark the learning algorithms. MNIST (LeCun, 1998) contains 70,000 2828 handwritten digit images of class 0-9. CIFAR-10 (Krizhevsky et al., 2009) contains 60,000 3232 natural images of 10 semantic classes. ImageNet (Deng et al., 2009) contains 1.3 million natural images of 1000 classes, which we resized to 224224. For CIFAR-10 and ImageNet, we applied both supervised learning and contrastive learning. For MNIST, we applied supervised learning only. We designed different configurations of the LocalMixer architecture for each dataset, listed in Table 2.
Data augmentation.
For MNIST and CIFAR-10 supervised experiments, we do not apply data augmentation. Data augmentation on ImageNet follows the open source implementation by Grill et al. (2020). Because forward gradient suffers from variance, we apply weaker augmentations for contrastive learning experiments, increasing the area lower bound for random crops from 0.08 to 0.3-0.5. We find that this change has relatively little effect on the performance of backprop.
Main results.
Our main results are shown in Table 3 and Table 4. In supervised experiments, there is almost no cost of introducing local greedy losses, and our local forward gradient method can match the test error of backprop on MNIST and CIFAR. Note that LG-FG-A fails to overfit the training set to 0% error when trained without data augmentation. This suggests that variance could still be an issue. For CIFAR-10 contrastive learning, our method obtains an error rate approaching that obtained by backprop (26.81% vs. 17.53%), and most of the gap is due to greedy learning vs. gradient estimation (6.09% vs. 3.19%). On ImageNet, we achieve reasonable performance compared to backprop (58.37% vs. 36.82% for supervised and 73.24% vs. 55.66% for contrastive). However, we find that the error due to greediness grows as the problem gets more complex and requires more layers to cooperate. We significantly outperform the FA family on ImageNet (by 25% for supervised and 10% for contrastive). Interestingly, local greedy FA also performs better than global feedback alignment, which suggests that the benefit of local learning transfers to other types of gradient approximation. TP-based methods were evaluated in Bartunov et al. (2018) and were found to be worse than FA on ImageNet. In sum, although there is still some noticeable gap between our method and backprop, we have made a large stride forward compared to backprop-free algorithms. More results are included in the Appendix 14.
|
|
|
|
|
|
|
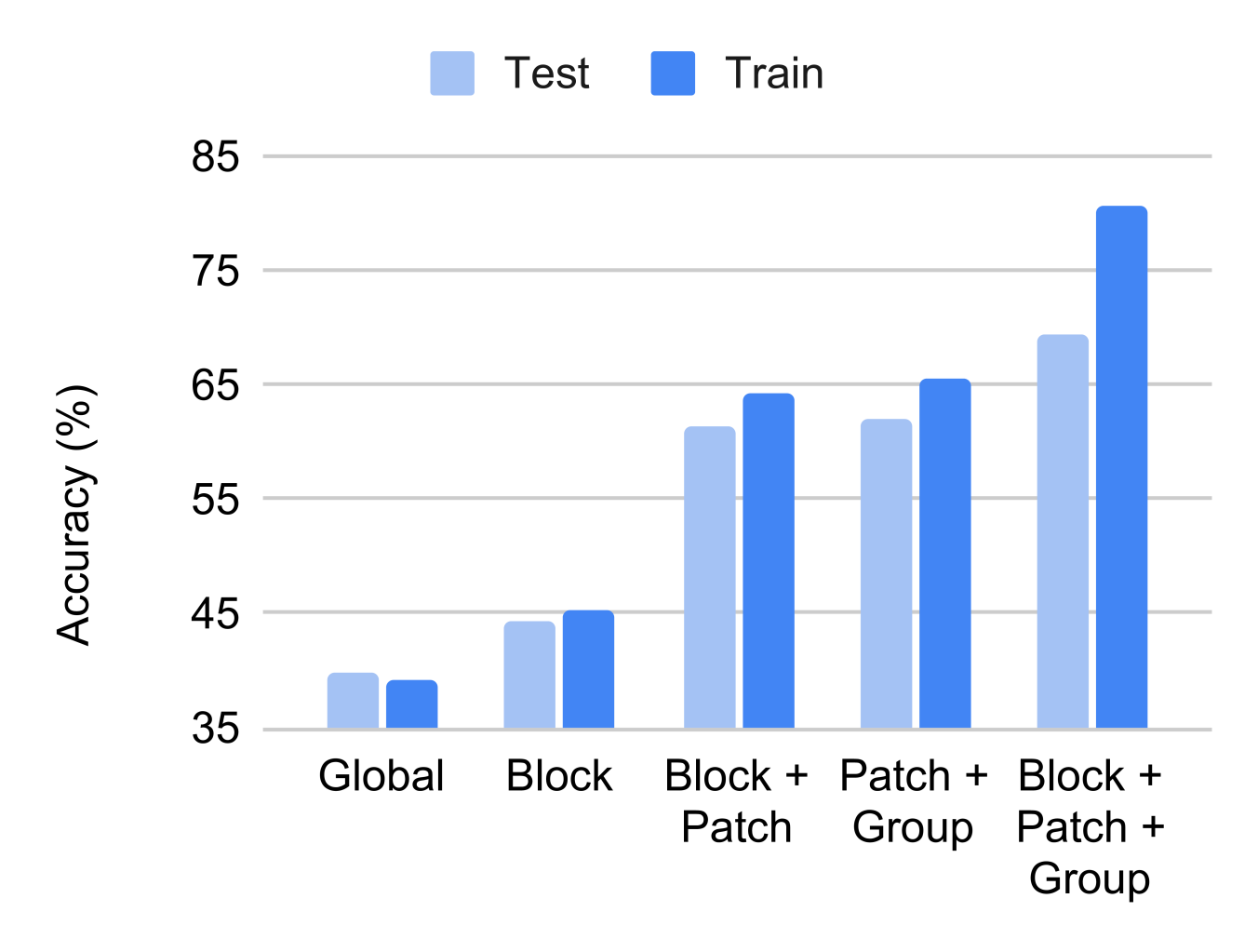
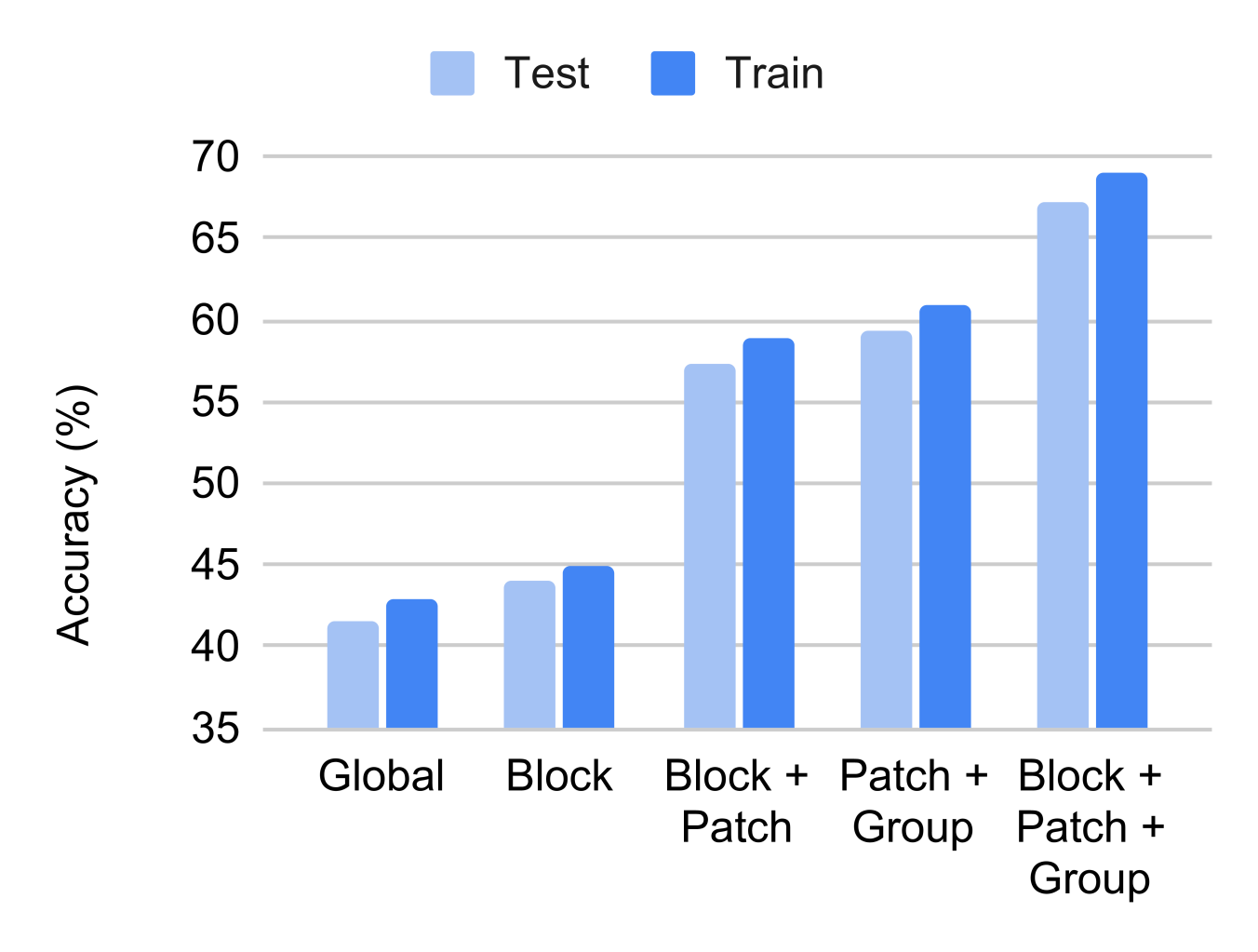
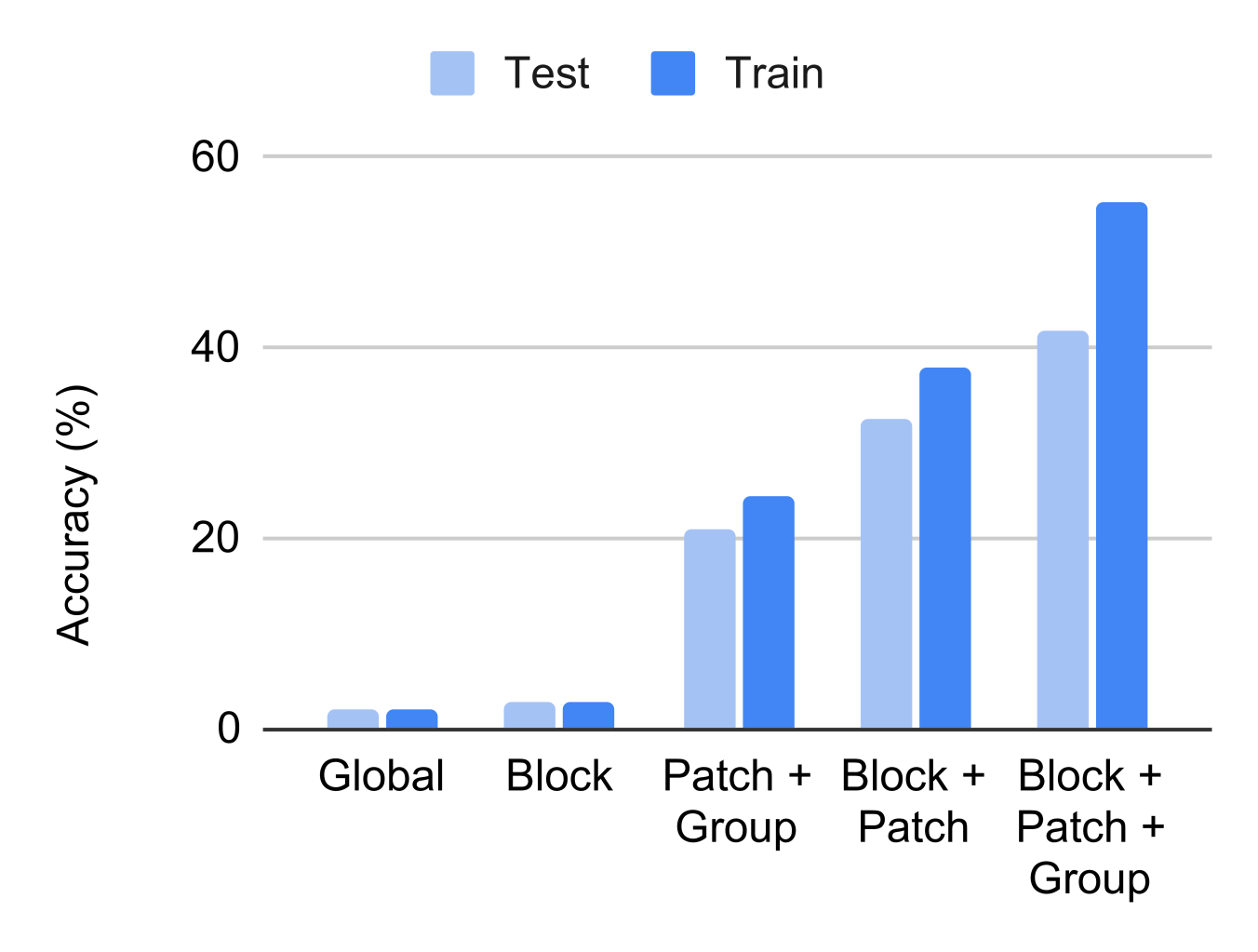
Effect of local losses.
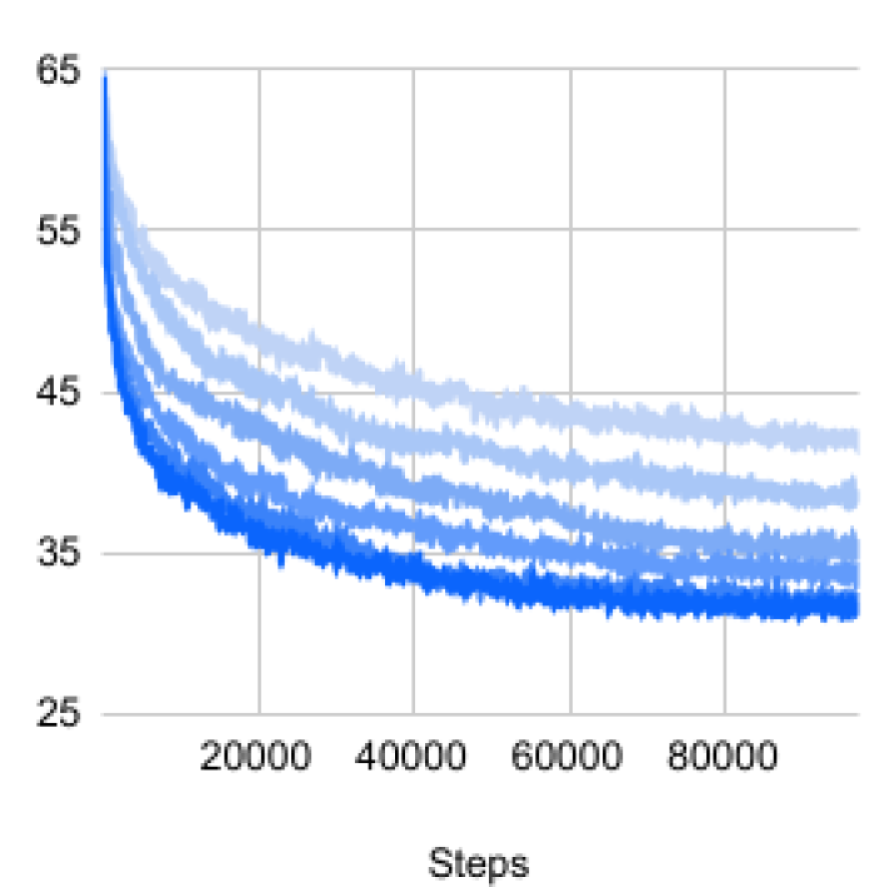
In Figure 6 we ablate the benefit of placing local losses at different locations: blockwise, patchwise and groupwise. A combination of all three is the strongest. Global perturbation learning fails to learn as the accuracy is similar to initializing with random weights.
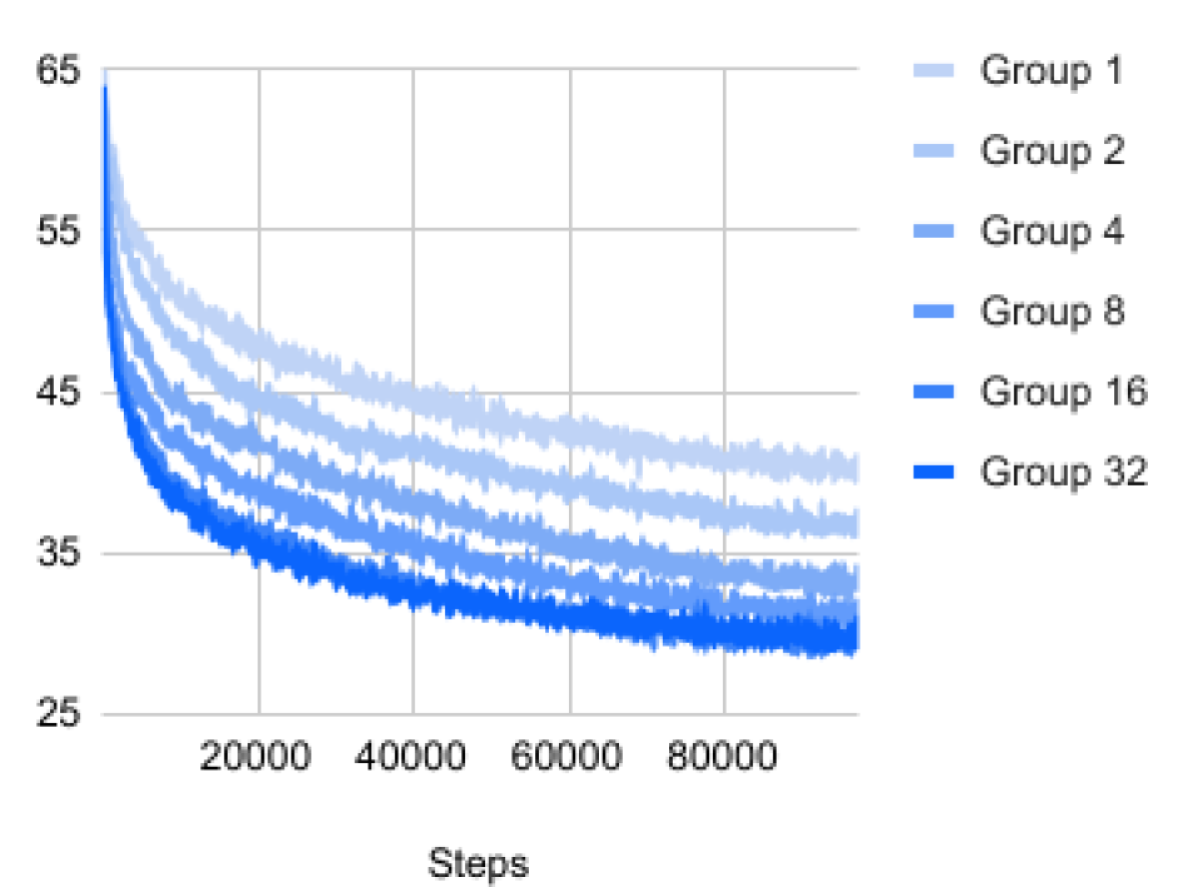
Effect of groups.
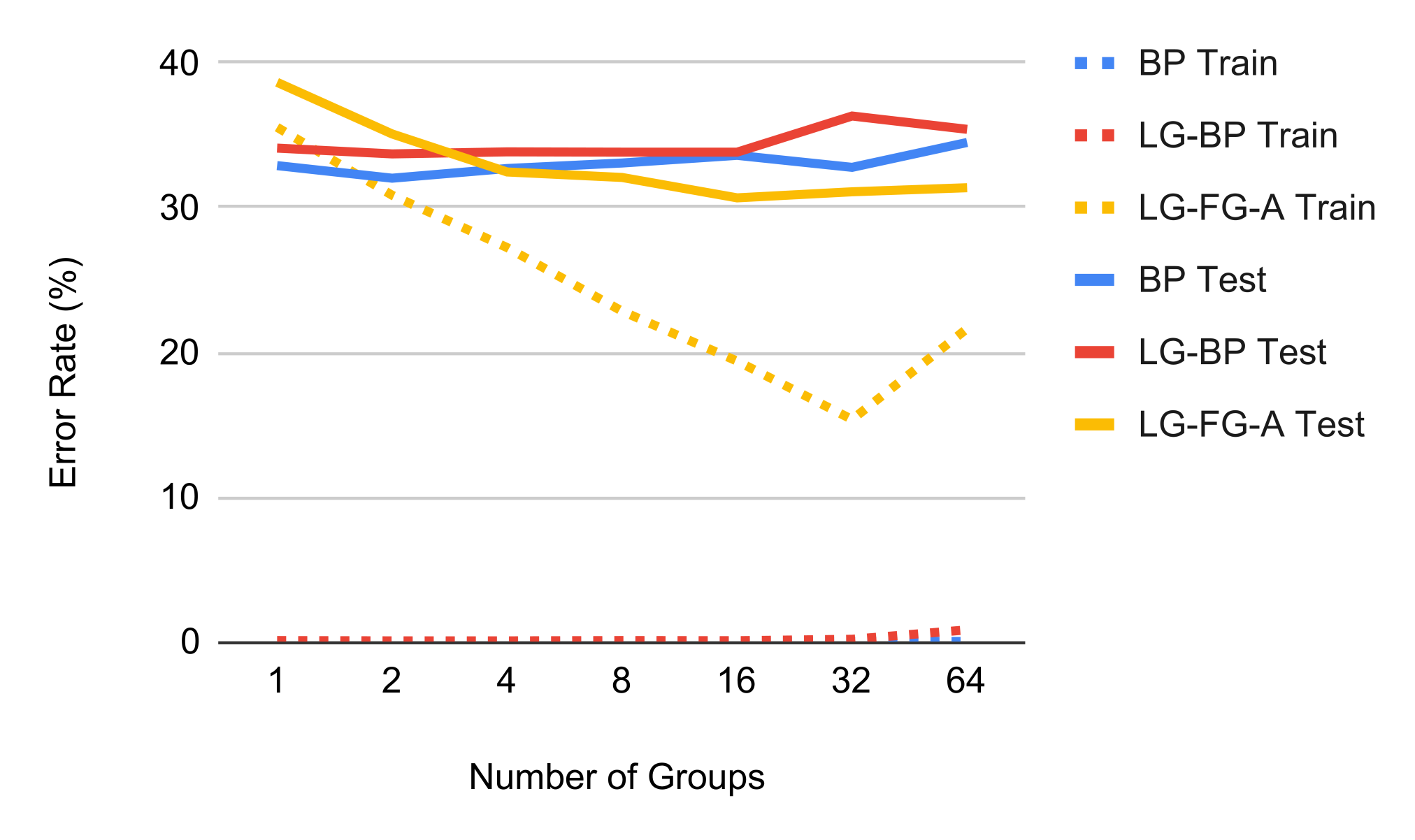
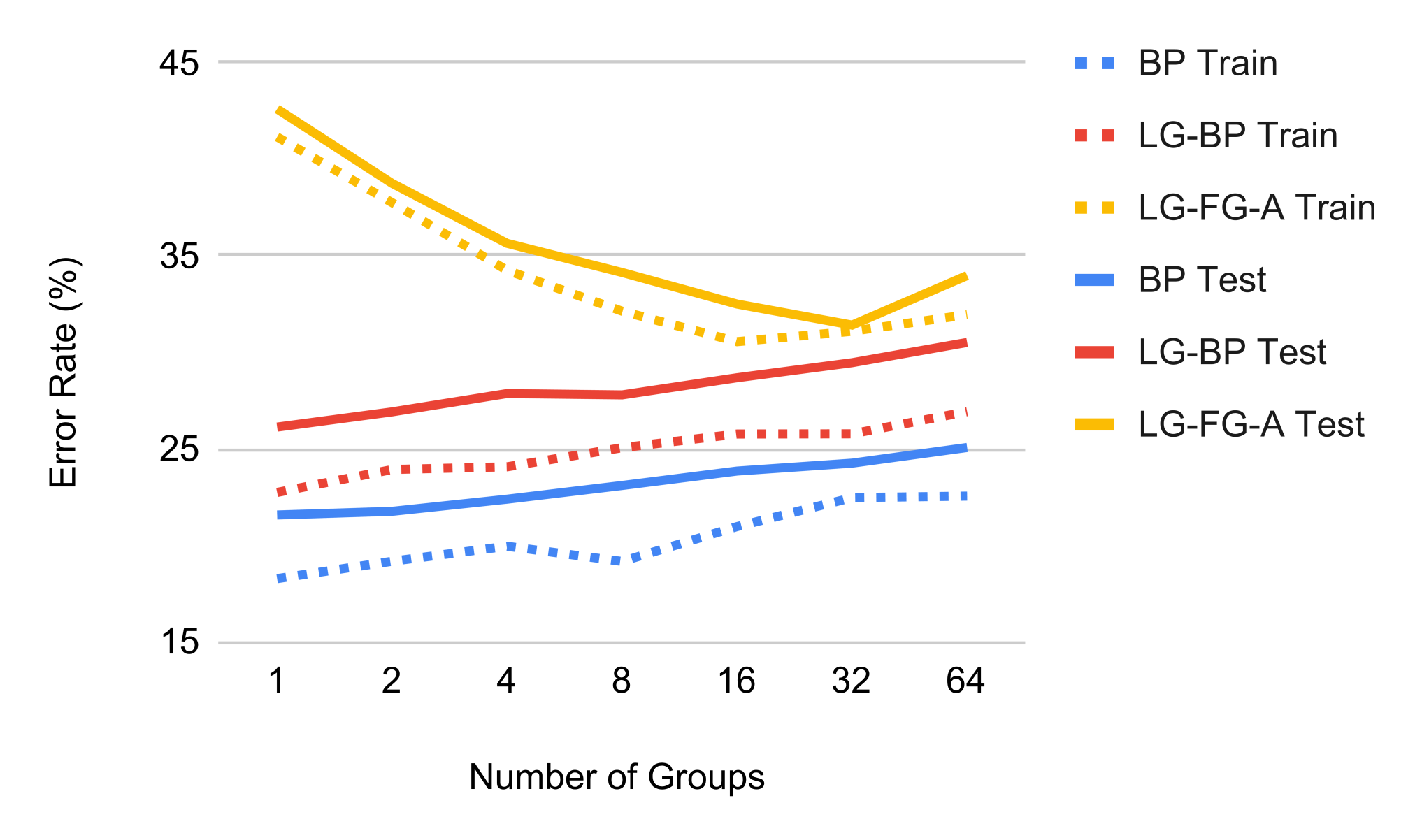
In Figure 7 we investigate the effect of different number of groups by showing the training curves. Adding more groups bring significant improvement to local perturbation learning in terms of lowering both training and test errors, but the effect vanishes around 8 channels / group.
7 Conclusion
It is often believed that perturbation-based learning cannot scale to large and deep networks. We show that this is to some extent true because the gradient estimation variance grows with the number of hidden dimensions for activity perturbation, and is even worse for shared weight perturbation. But more optimistically, we show that a huge number of local greedy losses can help forward gradient learning scale much better. We explored blockwise, patchwise, and groupwise local losses, and a combination of all three, with a total of a quarter of a million losses in one of the larger networks, performs the best. Local activity-perturbed forward gradient performs better than previous backprop-free algorithms on larger networks. The idea of local losses opens up opportunities for different loss designs and sheds light on the search for biologically plausible learning algorithms in the brain and alternative computing devices.
Acknowledgment
We thank Timothy Lillicrap for his helpful feedback on our earlier draft.
References
- Synaptic plasticity: taming the beast. Nature neuroscience 3 (11), pp. 1178–1183. Cited by: §2.
- Deep learning without weight transport. In Advances in Neural Information Processing Systems 32, NeurIPS, Cited by: §2.
- Layer normalization. CoRR abs/1607.06450. Cited by: §5.
- A theory of local learning, the learning channel, and the optimality of backpropagation. Neural Networks 83, pp. 51–74. External Links: Document Cited by: §2.
- Neuronlike adaptive elements that can solve difficult learning control problems. IEEE Transactions on Systems, Man, and Cybernetics (5), pp. 834–846. Cited by: §3.2.
- Assessing the scalability of biologically-motivated deep learning algorithms and architectures. In Advances in Neural Information Processing Systems 31, NeurIPS, Cited by: §1, §2, §6.
- Gradients without backpropagation. CoRR abs/2202.08587. Cited by: §1, §2, §3.2, §6, §8, Proposition 1.
- Greedy layerwise learning can scale to imagenet. In Proceedings of the 36th International Conference on Machine Learning, ICML, Cited by: §1, §2, §4, §6.
- Decoupled greedy learning of cnns. In Proceedings of the 37th International Conference on Machine Learning, ICML, Cited by: §2.
- Greedy layer-wise training of deep networks. In Advances in Neural Information Processing Systems 19, NIPS, Cited by: §2.
- STDP as presynaptic activity times rate of change of postsynaptic activity approximates back-propagation. Neural Computation 10. Cited by: §3.5.
- How auto-encoders could provide credit assignment in deep networks via target propagation. CoRR abs/1407.7906. Cited by: §2.
- Theory for the development of neuron selectivity: orientation specificity and binocular interaction in visual cortex. Journal of Neuroscience 2 (1), pp. 32–48. Cited by: §2.
- JAX: composable transformations of Python+NumPy programs External Links: Link Cited by: §3.1, §5.
- A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, ICML, Cited by: §4.
- Credit assignment through broadcasting a global error vector. In Advances in Neural Information Processing Systems 34, NeurIPS, Cited by: §2.
- Imagenet: a large-scale hierarchical image database. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Cited by: §6.
- An image is worth 16x16 words: transformers for image recognition at scale. In 9th International Conference on Learning Representations, ICLR, Cited by: §4.
- Gradient learning in spiking neural networks by dynamic perturbation of conductances. Physical review letters 97 (4), pp. 048104. Cited by: §1, §1, §2, §3.3.
- Interlocking backpropagation: improving depthwise model-parallelism. CoRR abs/2010.04116. Cited by: §2.
- Bootstrap your own latent - A new approach to self-supervised learning. In Advances in Neural Information Processing Systems 33, NeurIPS, Cited by: §11, §11, §6.
- The organization of behavior: a neuropsychological theory. J. Wiley; Chapman & Hall. Cited by: §2.
- Learning representations by recirculation. In Neural Information Processing Systems, Cited by: §2.
- A fast learning algorithm for deep belief nets. Neural Comput. 18 (7), pp. 1527–1554. External Links: Document Cited by: §2.
- Distilling the knowledge in a neural network. CoRR abs/1503.02531. External Links: 1503.02531 Cited by: §4.
- How to do backpropagation in a brain. In Invited talk at the NIPS 2007 deep learning workshop, Cited by: §3.5.
- Deep roots: improving CNN efficiency with hierarchical filter groups. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Cited by: §4.
- Batch normalization: accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML, Cited by: §5.
- Weight perturbation: an optimal architecture and learning technique for analog vlsi feedforward and recurrent multilayer networks. IEEE Transactions on Neural Networks 3 (1), pp. 154–157. Cited by: §2.
- Backpropagation without weight transport. In Proceedings of IEEE International Conference on Neural Networks, ICNN, Cited by: §2.
- Learning multiple layers of features from tiny images. Cited by: §6.
- ImageNet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25, NIPS, Cited by: §4, §5.
- Parallel training of deep networks with local updates. CoRR abs/2012.03837. Cited by: §2.
- GEMINI: gradient estimation through matrix inversion after noise injection. In Advances in Neural Information Processing Systems, NIPS, Vol. 1. Cited by: §1, §2, §3.3.
- A learning scheme for asymmetric threshold networks. Proceedings of COGNITIVA 85 (537), pp. 599–604. Cited by: §1.
- The mnist database of handwritten digits. External Links: Link Cited by: §6.
- Difference target propagation. In Joint european conference on machine learning and knowledge discovery in databases, pp. 498–515. Cited by: §2.
- How important is weight symmetry in backpropagation?. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, AAAI, Cited by: §2.
- Random synaptic feedback weights support error backpropagation for deep learning. Nature Communications 7 (1), pp. 13276. External Links: ISSN 2041-1723, Document Cited by: §1, §2, §6.
- Backpropagation and the brain. Nature Reviews Neuroscience 21 (6), pp. 335–346. External Links: ISSN 1471-0048, Document Cited by: §2.
- Putting an end to end-to-end: gradient-isolated learning of representations. In Advances in Neural Information Processing Systems 32, NeurIPS, Cited by: §1, §2, §4, §6.
- Training neural networks with local error signals. In Proceedings of the 36th International Conference on Machine Learning, ICML, Cited by: §2, §6.
- Direct feedback alignment provides learning in deep neural networks. In Advances in Neural Information Processing Systems 29, NeurIPS, Cited by: §1, §2.
- Simplified neuron model as a principal component analyzer. Journal of mathematical biology 15 (3), pp. 267–273. Cited by: §2.
- Local learning with neuron groups. In From Cells to Societies: Collective Learning Across Scales - ICLR 2022 Workshop, Cited by: §2, §4.
- Fast exact multiplication by the hessian. Neural computation 6 (1), pp. 147–160. Cited by: §1, §2.
- Semi-supervised learning with ladder networks. In Advances in Neural Information Processing Systems 28, NIPS, Cited by: §2.
- Normalizing the normalizers: comparing and extending network normalization schemes. In Proceedings of the 5th International Conference on Learning Representations, ICLR, Cited by: §5.
- Learning internal representations by error propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Vol. 1: Foundations, Cambridge, MA, USA, pp. 318–362. External Links: ISBN 026268053X Cited by: §1.
- Evolution strategies as a scalable alternative to reinforcement learning. CoRR abs/1703.03864. External Links: 1703.03864 Cited by: §2.
- A neural substrate of prediction and reward. Science 275 (5306), pp. 1593–1599. Cited by: §2.
- Learning in spiking neural networks by reinforcement of stochastic synaptic transmission. Neuron 40 (6), pp. 1063–1073. Cited by: §1, §2, §3.2.
- A rapid and efficient learning rule for biological neural circuits. BioRxiv. Cited by: §2.
- Learning by directional gradient descent. In Proceedings of the 10th International Conference on Learning Representations, ICLR, Cited by: §1, §2.
- Evolving neural networks through augmenting topologies. Evol Comput 10 (2), pp. 99–127. Cited by: §2.
- MLP-mixer: an all-mlp architecture for vision. In Advances in Neural Information Processing Systems 34, NeurIPS, Cited by: §1, §5, §5.
- Representation learning with contrastive predictive coding. CoRR abs/1807.03748. Cited by: §4.
- Attention is all you need. In Advances in Neural Information Processing Systems 30, NIPS, Cited by: §4.
- Online learning with gated linear networks. arXiv preprint arXiv:1712.01897. Cited by: §2.
- Gated linear networks. In Proceedings of the AAAI Conference on Artificial Intelligence, AAAI, Cited by: §2.
- Stacked denoising autoencoders: learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 11, pp. 3371–3408. External Links: Document Cited by: §2.
- Revisiting locally supervised learning: an alternative to end-to-end training. In 9th International Conference on Learning Representations, ICLR, Cited by: §2.
- Flipout: efficient pseudo-independent weight perturbations on mini-batches. In 6th International Conference on Learning Representations, ICLR, Cited by: §9.
- A simple automatic derivative evaluation program. Commun. ACM 7 (8), pp. 463–464. Cited by: §2.
- Beyond regression:" new tools for prediction and analysis in the behavioral sciences. Ph. D. dissertation, Harvard University. Cited by: §1.
- Learning curves for stochastic gradient descent in linear feedforward networks. Advances in Neural Information Processing Systems 16, NIPS. Cited by: §2.
- Genetic reinforcement learning for neurocontrol problems. Mach. Learn. 13, pp. 259–284. Cited by: §2.
- Theories of error back-propagation in the brain. Trends in Cognitive Sciences 23 (3), pp. 235–250. External Links: ISSN 1364-6613, Document Cited by: §2.
- Adaptive switching circuits. Technical report Stanford Univ Ca Stanford Electronics Labs. Cited by: §2.
- 30 years of adaptive neural networks: perceptron, madaline, and backpropagation. Proc. IEEE 78 (9), pp. 1415–1442. Cited by: §1, §2, §3.3.
- A learning algorithm for continually running fully recurrent neural networks. Neural computation 1 (2), pp. 270–280. Cited by: §2.
- Activation sharing with asymmetric paths solves weight transport problem without bidirectional connection. In Advances in Neural Information Processing Systems 34, NeurIPS, Cited by: §2.
- Group normalization. In 15th European Conference on Computer Vision, ECCV, Cited by: §5.
- Biologically-plausible learning algorithms can scale to large datasets. In Proceedings of the 7th International Conference on Learning Representations, ICLR, Cited by: §2.
- Aggregated residual transformations for deep neural networks. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Cited by: §4.
- Spike-based learning rules and stabilization of persistent neural activity. Advances in Neural Information Processing Systems 12, NIPS. Cited by: §1, §2, §3.2.
- LoCo: local contrastive representation learning. In Advances in Neural Information Processing Systems 33, NeurIPS, Cited by: §1, §2.
8 Proofs of Unbiasedness
In this section, we show the unbiasedness of and . The first proof was given by Baydin et al. (2022).
Proposition 1.
is an unbiased gradient estimator if are independent zero-mean uni-variance random variables (Baydin et al., 2022).
Proof.
We can rewrite the weight perturbation estimator as
| (7) |
Note that since each dimension of is an independent zero-mean uni-variance random variable, , , and if .
| (8) | ||||
| (9) | ||||
| (10) | ||||
| (11) |
∎
Proposition 2.
is an unbiased gradient estimator if are independent zero-mean uni-variance random variables.
Proof.
The true gradient to the weights is the product between and . Therefore, we can rewrite the weight perturbation estimator as
| (12) | ||||
| (13) | ||||
| (14) |
Since each dimension of is an independent zero-mean uni-variance random variable, , , and if .
| (15) | ||||
| (16) | ||||
| (17) | ||||
| (18) |
∎
9 Proofs of Variances
We followed Wen et al. (2018) and show that the variance of the gradient estimators can be decomposed.
Lemma 1.
The variance of the gradient estimator can be decomposed into three parts:
, where
,
,
.
Proof.
By the law of total variance,
| (19) |
The first term comes from the gradient variance from data sampling, and it vanishes as batch size grows:
| (20) | ||||
| (21) | ||||
| (22) | ||||
| (23) | ||||
| (24) | ||||
| (25) |
The second term comes from the gradient estimation variance:
| (26) | ||||
| (27) | ||||
| (28) | ||||
| (29) | ||||
| (30) | ||||
| (31) |
∎
Remark.
is the variance of the gradient estimator in the deterministic case, and measures the correlation between different gradient estimation within the batch. The is zero if the perturbations are independent, and non-zero if the perturbations are shared within the mini-batch.
Proposition 3.
Let be the size of the weight matrix, the element-wise average variance of the weight perturbed gradient estimator with a batch size is if the perturbations are shared across the batch, and if they are independent, where is the element-wise average variance of the true gradient, and is the element-wise average squared gradient.
Proof.
We first derive .
| (32) | ||||
| (33) | ||||
| (34) | ||||
| (35) | ||||
| (36) | ||||
| (37) | ||||
| (38) | ||||
| (39) | ||||
| (40) | ||||
| (41) | ||||
| (42) | ||||
| (43) | ||||
| (44) | ||||
| (45) |
| (46) | ||||
| (47) | ||||
| (48) |
is nonzero if the perturbations are shared within a batch. Assuming that the perturbations are shared,
| (49) | ||||
| (50) | ||||
| (51) | ||||
| (52) | ||||
| (53) | ||||
| (54) | ||||
| (55) | ||||
| (56) | ||||
| (57) | ||||
| (58) | ||||
| (59) | ||||
| (60) |
| (61) | ||||
| (62) | ||||
| (63) | ||||
| (64) | ||||
| (65) | ||||
| (66) | ||||
| (67) | ||||
| (68) | ||||
| (69) | ||||
| (70) | ||||
| (71) | ||||
| (72) | ||||
| (73) | ||||
| (74) |
Lastly, we average the variance across all weight dimensions:
| (75) | ||||
| (76) | ||||
| (77) | ||||
| (78) | ||||
| (79) | ||||
| (80) | ||||
| (81) | ||||
| (82) | ||||
| (83) |
If the perturbations are independent, we show that is 0.
| (84) | ||||
| (85) | ||||
| (86) | ||||
| (87) | ||||
| (88) | ||||
| (89) | ||||
| (90) |
| (91) | ||||
| (92) | ||||
| (93) | ||||
| (94) | ||||
| (95) | ||||
| (96) | ||||
| (97) | ||||
| (98) | ||||
| (99) | ||||
| (100) | ||||
| (101) | ||||
| (102) | ||||
| (103) | ||||
| (104) | ||||
| (105) |
Then the average variance becomes:
| (106) | ||||
| (107) | ||||
| (108) | ||||
| (109) | ||||
| (110) | ||||
| (111) |
∎
Proposition 4.
Let be the size of the weight matrix, the element-wise average variance of the activity perturbed gradient estimator with a batch size is if the perturbations are shared across the batch, and if they are independent, where is the element-wise average variance of the true gradient, and is the element-wise average squared gradient.
Proof.
| (112) | ||||
| (113) | ||||
| (114) | ||||
| (115) | ||||
| (116) | ||||
| (117) | ||||
| (118) | ||||
| (119) | ||||
| (120) |
| (121) | ||||
| (122) | ||||
| (123) | ||||
| (124) | ||||
| (125) | ||||
| (126) | ||||
| (127) | ||||
| (128) | ||||
| (129) | ||||
| (130) |
is nonzero if the perturbations are shared within a batch. Assuming that the perturbations are shared,
| (131) | ||||
| (132) | ||||
| (133) | ||||
| (134) | ||||
| (135) |
| (136) | ||||
| (137) | ||||
| (138) | ||||
| (139) | ||||
| (140) | ||||
| (141) | ||||
| (142) | ||||
| (143) | ||||
| (144) | ||||
| (145) | ||||
| (146) | ||||
| (147) | ||||
| (148) | ||||
| (149) | ||||
| (150) |
| (151) | ||||
| (152) | ||||
| (153) | ||||
| (154) |
Then we compute the average variance across all weight dimensions (for shared perturbation):
| (155) | ||||
| (156) | ||||
| (157) | ||||
| (158) | ||||
| (159) | ||||
| (160) | ||||
| (161) | ||||
| (162) | ||||
| (163) |
If the perturbations are independent, we show that is 0.
| (164) | ||||
| (165) |
| (166) | ||||
| (167) | ||||
| (168) | ||||
| (169) | ||||
| (170) | ||||
| (171) | ||||
| (172) | ||||
| (173) | ||||
| (174) | ||||
| (175) | ||||
| (176) | ||||
| (177) | ||||
| (178) | ||||
| (179) | ||||
| (180) | ||||
| (181) | ||||
| (182) |
| (183) | ||||
| (184) | ||||
| (185) |
Then the average variance becomes:
| (186) | ||||
| (187) | ||||
| (188) | ||||
| (189) | ||||
| (190) | ||||
| (191) |
∎
10 Numerical Simulation of Variances
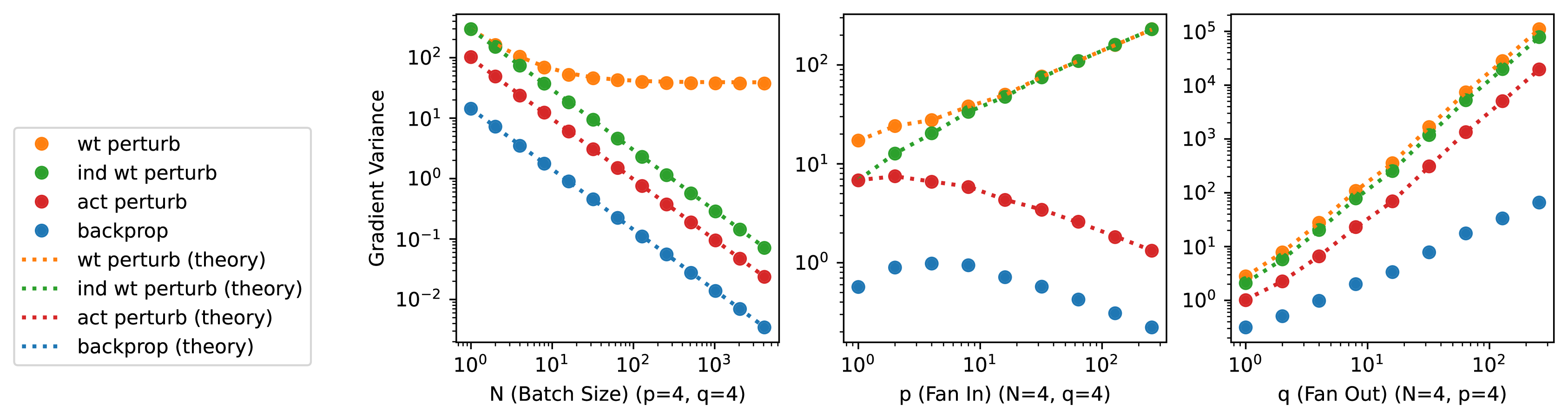
In Figure 8, we ran numerical simulation experiments to verify our analytical variance properties. We used a multi-layer network with 4 input units, 4 hidden units, 1 output unit, a activation function, and the mean squared error loss. We varied the batch size () between 1 and 4096. We tested the gradient estimator of the first layer weights using 5000 random samples. We also calculated the theoretical variance by applying the gradient norm and gradient variance constants found by backprop, from 5000 mini-batch true gradients. We then fixed the batch size to be 4 and vary the number of input units (, fan in) and the number of hidden units (, fan out) between 1 and 256. The theoretical variance for backprop was only computed for the batch size experiment since it is an inverse relationship (), but for fan in and fan out, we do not aim to analyze the theoretical variances here. “wt perturb” stands for weight perturbation with shared noise; “ind wt perturb” stands for weight perturbation with independent noise; and “act perturb” stands for activity perturbation with independent noise. Note that indepedent weight perturbation is much more costly to compute in neural networks. As shown in the figure, the empirical variances match very well with our theoretical predictions.
11 Training Details
Here we provide more training details.
Mnist.
We use a batch size of 128, and the SGD optimizer with learning rate 0.01 and momentum 0.9 for a total of 1000 epochs with no data augmentation and a linear learning rate decay schedule.
Cifar-10.
For the supervised experiments, we use a batch size of 128 and the SGD optimizer with learning rate 0.01 and momentum 0.9 for a total of 200 epochs with no data augmentation and a linear learning rate decay schedule. For the contrastive M/8 experiments, we use a batch size of 512 and the SGD optimizer with learning rate 1.0 and momentum 0.9 for a total of 1000 epochs with BYOL data augmentation using area crop lower bound to be 0.5 and a cosine decay schedule with a warm-up period of 10 epochs. For the contrastive L/8 experiments, we use a batch size of 2048 and the SGD optimizer with learning rate 4.0 and momentum 0.9 for a total of 1000 epochs with BYOL data augmentation (Grill et al., 2020) using area crop lower bound to be 0.3 and a cosine decay schedule with a warm-up period of 10 epochs.
ImageNet.
For the supervised experiments, we use a batch size of 256 and the SGD optimizer with learning rate 0.05 and momentum 0.9 for a total of 120 epochs with BYOL data augmentation (Grill et al., 2020) using area crop lower bound to be 0.3 and a cosine learning rate decay schedule with a warm-up period of 10 epochs. For the contrastive experiments, we use a batch size of 2048 and the LARS optimizer with learning rate 0.1 and momentum 0.9 for a total of 800 epochs with BYOL data augmentation (Grill et al., 2020) using area crop lower bound to be 0.08 and a cosine learning rate decay schedule with a warm-up period of 10 epochs.
12 Fused JVP/VJP Details
In Algorithm 1, we provide a JAX code snippet implementing fused operators for the supervised cross entropy loss. “Fused” here means that we package several operations into one function. In the supervised cross entropy loss, we combine average pooling, channel concatenation, a linear classifier layer, and cross entropy all together. Key steps and expected tensor shapes are annotated in the comments. The fused InfoNCE loss implementation will be included in our full code release.
13 LocalMixer Architecture
In Algorithm 2, we provide code in JAX style that implements our proposed LocalMixer architecture.
14 Additional Results
In this section we provide additional experimental results.
Normalization scheme.
Table 5 compares different normalization schemes. Layer normalization (LN) is often better than batch normalization (BN) on our mixer architecture. Local LN is better on contrastive learning experiments and achieves lower error rates using forward gradient learning. Although in our main paper, backprop were used in normalization layers, backprop is not necessary for Local LN, c.f. “NG” (No Gradient) columns in Table 5.
Place of normalization.
We investigate the places where we add normalization layers. Traditionally, normalization is added after linear layers. In MLPMixer, LN is added at the beginning of each block. With our forward gradient learning, it is now a question of which location is the optimal design. Adding it after the linear layer has the advantage of shaping the activations to be more well behaved, which can make perturbation learning more effective. Adding it before the linear layer can also help reduce the variance since the inputs always get multiplied with the gradient of the output activity. The results are reported in Table 6. Adding normalization both before and after the linear layer helps forward gradient to achieve lower training errors. While this could result in some overfitting on supervised learning, it is good for contrastive learning which needs more model capacity. This is reasonable as forward gradient introduce a lot of variances, and more normalization layers help achieve better training performance.
| Supervised M/8/16 | Contrastive M/8/16 | |||||||
| BP | LG-BP | LG-FG-A | LG-FG-A (NG) | BP | LG-BP | LG-FG-A | LG-FG-A (NG) | |
| BN | 30.38 / 0.00 | 33.41 / 5.41 | 32.84 / 23.09 | 33.48 / 20.80 | 27.56 / 24.39 | 30.27 / 28.03 | 35.47 / 32.71 | 37.41 / 31.52 |
| LN | 30.55 / 0.00 | 33.17 / 7.09 | 29.03 / 17.63 | 29.33 / 19.26 | 23.52 / 20.71 | 27.41 / 24.73 | 34.21 / 31.38 | 36.24 / 34.12 |
| Local LN | 32.89 / 0.00 | 33.84 / 0.05 | 30.68 / 19.39 | 30.44 / 17.12 | 23.24 / 21.03 | 28.42 / 25.20 | 32.89 / 31.01 | 32.25 / 30.17 |
| Supervised M/8/16 | Contrastive M/8/16 | |||||
| LN | BP | LG-BP | LG-FG-A | BP | LG-BP | LG-FG-A |
| Begin Block | 31.43 / 0.00 | 34.73 / 1.45 | 34.89 / 31.11 | 23.27 / 20.69 | 25.82 / 22.96 | 89.93 / 90.71 |
| Before Linear | 32.50 / 0.00 | 34.15 / 0.05 | 33.88 / 27.94 | 22.62 / 20.38 | NaN / NaN | 35.01 / 32.91 |
| After Linear | 30.38 / 0.00 | 29.83 / 0.44 | 29.35 / 23.19 | 26.50 / 23.98 | 28.97 / 26.67 | 34.10 / 33.18 |
| Before + After Linear | 33.62 / 0.00 | 33.84 / 0.05 | 30.68 / 19.39 | 23.24 / 21.03 | 28.42 / 25.20 | 32.89 / 31.01 |
|
|
Effect of groups.
We provide additional results summarizing the training and test performance of adding more groups in Figure 9. Backprop and local greedy backprop always achieve zero training error with increasing number of groups on CIFAR-10 supervised, but adding groups has a significant benefit lowering training errors for forward gradient. This suggests that the main opponent here is still the gradient estimation variance, and lowering training errors can generally make test errors lower too; on the other hand adding groups have negligible effect on backprop. For contrastive learning, here the task requires higher model capacity, and adding groups effectively reduce the model capacity by introducing sparsity in the weight matrix. As a result, we observe a slight drop of less than 5% performance on both backprop and local greedy backprop. By contrast, forward gradient gains over 10% of performance by adding 16 groups.