LoCo: Local Contrastive Representation Learning
Abstract
Deep neural nets typically perform end-to-end backpropagation to learn the weights, a procedure that creates synchronization constraints in the weight update step across layers and is not biologically plausible. Recent advances in unsupervised contrastive representation learning invite the question of whether a learning algorithm can also be made local, that is, the updates of lower layers do not directly depend on the computation of upper layers. While Greedy InfoMax Löwe et al. (2019) separately learns each block with a local objective, we found that it consistently hurts readout accuracy in state-of-the-art unsupervised contrastive learning algorithms, possibly due to the greedy objective as well as gradient isolation. In this work, we discover that by overlapping local blocks stacking on top of each other, we effectively increase the decoder depth and allow upper blocks to implicitly send feedbacks to lower blocks. This simple design closes the performance gap between local learning and end-to-end contrastive learning algorithms for the first time. Aside from standard ImageNet experiments, we also show results on complex downstream tasks such as object detection and instance segmentation directly using readout features.
1 Introduction
Most deep learning algorithms nowadays are trained using backpropagation in an end-to-end fashion: training losses are computed at the top layer and weight updates are computed based on the gradient that flows from the very top. Such an algorithm requires lower layers to “wait” for upper layers, a synchronization constraint that seems very unnatural in truly parallel distributed processing. Indeed, there are evidences that weight synapse updates in the human brain are achieved through local learning, without waiting for neurons in other parts of the brain to finish their jobs Caporale and Dan (2008); Bengio et al. (2015). In addition to biological plausibility aims, local learning algorithms can also significantly reduce memory footprint during training, as they do not require saving the intermediate activations after each local module finish its calculation. With these synchronization constraints removed, one can further enable model parallelism in many deep network architectures Narayanan et al. (2019) for faster parallel training and inference.
One main objection against local learning algorithms has always been the need for supervision from the top layer. This belief has recently been challenged by the success of numerous self-supervised contrastive learning algorithms Tian et al. (2019); He et al. (2019a); Misra and van der Maaten (2019); Chen et al. (2020a), some of which can achieve matching performance compared to supervised counterparts, meanwhile using zero class labels during the representation learning phase. Indeed, Löwe et al. Löwe et al. (2019) show that they can separately learn each block of layers using local contrastive learning by putting gradient stoppers in between blocks. While the authors show matching or even sometimes superior performance using local algorithms, we found that their gradient isolation blocks still result in degradation in accuracy in state-of-the-art self-supervised learning frameworks, such as SimCLR Chen et al. (2020a). We hypothesize that, due to gradient isolation, lower layers are unaware of the existence of upper layers, and thus failing to deliver the full capacity of a deep network when evaluating on large scale datasets such as ImageNet Deng et al. (2009).
To bridge the gradient isolation blocks and allow upper layers to influence lower layers while maintaining localism, we propose to group two blocks into one local unit and share the middle block simultaneously by two units. As shown in the right part of Fig. 1. Thus, the middle blocks will receive gradients from both the lower portion and the upper portion, acting like a gradient “bridge”. We found that such a simple scheme significantly bridges the performance gap between Greedy InfoMax Löwe et al. (2019) and the original end-to-end algorithm Chen et al. (2020a).
On ImageNet unsupervised representation learning benchmark, we evaluate our new local learning algorithm, named LoCo, on both ResNet He et al. (2016) and ShuffleNet Ma et al. (2018) architectures and found the conclusion to be the same. Aside from ImageNet object classification, we further validate the generalizability of locally learned features on other downstream tasks such as object detection and semantic segmentation, by only training the readout headers. On all benchmarks, our local learning algorithm once again closely matches the more costly end-to-end trained models.
We first review related literature in local learning rules and unsupervised representation learning in Section 2, and further elaborate the background and the two main baselines SimCLR Chen et al. (2020a) and Greedy InfoMax Löwe et al. (2019) in Section 3.2. Section 4 describes our LoCo algorithm in detail. Finally, in Section 5, we present ImageNet-1K Deng et al. (2009) results, followed by instance segmentation results on MS-COCO Lin et al. (2014) and Cityscapes Cordts et al. (2016).
2 Related Work
Neural network local learning rules:
Early neural networks literature, inspired by biological neural networks, makes use of local associative learning rules, where the change in synapse weights only depends on the pre- and post-activations. One classic example is the Hebbian rule Hebb (1949), which strengthens the connection whenever two neurons fire together. As this can result in numerical instability, various modifications were also proposed Oja (1982); Bienenstock et al. (1982). These classic learning rules can be empirically observed through long-term potentiation (LTP) and long term depression (LTD) events during spike-timing-dependent plasticity (STDP) Abbott and Nelson (2000); Caporale and Dan (2008), and various computational learning models have also been proposed Bengio et al. (2015). Local learning rules are also seen in learning algorithms such as restricted Boltzmann machines (RBM) Smolensky (1986); Hinton (2012); Hinton et al. (2006), greedy layer-wise training Bengio et al. (2006); Belilovsky et al. (2018) and TargetProp Bengio (2014). More recently, it is also shown to be possible to use a network to predict the weight changes of another network Jaderberg et al. (2017); Metz et al. (2019); Xiong et al. (2019), as well as to learn the meta-parameters of a plasticity rule Miconi et al. (2018, 2019). Direct feedback alignment Nøkland (2016) on the other hand proposed to directly learn the weights from the loss to each layer by using a random backward layer. Despite numerous attempts at bringing biological plausibility to deep neural networks, the performances of these learning algorithms are still far behind state-of-the-art networks that are trained via end-to-end backpropagation on large scale datasets. A major difference from prior literature is that, both GIM Löwe et al. (2019) and our LoCo use an entire downsampling stage as a unit of local computation, instead of a single convolutional layer. In fact, different downsampling stages have been found to have rough correspondence with the primate visual cortex Schrimpf et al. (2018); Zhuang et al. (2020), and therefore they can probably be viewed as better modeling tools for local learning. Nevertheless, we do not claim to have solved the local learning problem on a more granular level.
Unsupervised & self-supervised representation learning:
Since the success of AlexNet Krizhevsky et al. (2012), tremendous progress has been made in terms of learning representations without class label supervision. One of such examples is self-supervised training objectives Goyal et al. (2019), such as predicting context Doersch et al. (2015); Noroozi and Favaro (2016), predicting rotation Gidaris et al. (2018), colorization Zhang et al. (2016) and counting Noroozi et al. (2017). Representations learned from these tasks can be further decoded into class labels by just training a linear layer. Aside from predicting parts of input data, clustering objectives are also considered Zhuang et al. (2019); Caron et al. (2018). Unsupervised contrastive learning has recently emerged as a promising direction for representation learning van den Oord et al. (2018); Tian et al. (2019); He et al. (2019a); Misra and van der Maaten (2019); Chen et al. (2020a), achieving state-of-the-art performance on ImageNet, closing the gap between supervised training and unsupervised training with wider networks Chen et al. (2020a). Building on top of the InfoMax contrastive learning rule van den Oord et al. (2018), Greedy InfoMax (GIM) Löwe et al. (2019) proposes to learn each local stage with gradient blocks in the middle, effectively removing the backward dependency. This is similar to block-wise greedy training Belilovsky et al. (2018) but in an unsupervised fashion.
Memory saving and model parallel computation:
By removing the data dependency in the backward pass, our method can perform model parallel learning, and activations do not need to be stored all the time to wait from the top layer. GPU memory can be saved by recomputing the activations at the cost of longer training time Chen et al. (2016); Gruslys et al. (2016); Gomez et al. (2017), whereas local learning algorithms do not have such trade-off. Most parallel trainings of deep neural networks are achieved by using data parallel training, with each GPU taking a portion of the input examples and then the gradients are averaged. Although in the past model parallelism has also been used to vertically split the network Krizhevsky et al. (2012); Krizhevsky (2014), it soon went out of favor since the forward pass needs to be synchronized. Data parallel training, on the other hand, can reach generalization bottleneck with an extremely large batch size Shallue et al. (2019). Recently, Huang et al. (2019); Narayanan et al. (2019) proposed to make a pipeline design among blocks of neural networks, to allow more forward passes while waiting for the top layers to send gradients back. However, since they use end-to-end backpropagation, they need to save previous activations in a data buffer to avoid numerical errors when computing the gradients. By contrast, our local learning algorithm is a natural fit for model parallelism, without the need for extra activation storage and wait time.
3 Background: Unsupervised Contrastive Learning
In this section, we introduce relevant background on unsupervised contrastive learning using the InfoNCE loss van den Oord et al. (2018), as well as Greed InfoMax Löwe et al. (2019), a local learning algorithm that aims to learn each neural network stage with a greedy objective.
3.1 Unsupervised Contrastive Learning & SimCLR
Contrastive learning van den Oord et al. (2018) learns representations from data organized in similar or dissimilar pairs. During learning, an encoder is used to learn meaningful representations and a decoder is used to distinguish the positives from the negatives through the InfoNCE loss function van den Oord et al. (2018),
| (1) |
As shown above, the InfoNCE loss is essentially cross-entropy loss for classification with a temperature scale factor , where and are normalized representation vectors from the encoder. The positive pair needs to be classified among all pairs. Note that since the positive samples are defined as augmented version of the same example, this learning objective does not need any class label information. After learning is finished, the decoder part will be discarded and the encoder’s outputs will be served as learned representations.
Recently, Chen et al. proposed SimCLR Chen et al. (2020a), a state-of-the-art framework for contrastive learning of visual representations. It proposes many useful techniques for closing the gap between unsupervised and supervised representation learning. First, the learning benefits from a larger batch size (~2k to 8k) and stronger data augmentation. Second, it uses a non-linear MLP projection head instead of a linear layer as the decoder, making the representation more general as it is further away from the contrastive loss function. With 4 the channel size, it is able to match the performance of a fully supervised ResNet-50. In this paper, we use the SimCLR algorithm as our end-to-end baseline as it is the current state-of-the-art. We believe that our modifications can transfer to other contrastive learning algorithms as well.
3.2 Greedy InfoMax
As unsupervised learning has achieved tremendous progress, it is natural to ask whether we can achieve the same from a local learning algorithm. Greedy InfoMax (GIM) Löwe et al. (2019) proposed to learn representation locally in each stage of the network, shown in the middle part of Fig. 1. It divides the encoder into several stacked modules, each with a contrastive loss at the end. The input is forward-propagated in the usual way, but the gradients do not propagate backward between modules. Instead, each module is trained greedily using a local contrastive loss. This work was proposed prior to SimCLR and achieved comparable results to CPC van den Oord et al. (2018), an earlier work, on a small scale dataset STL-10 Coates et al. (2011). In this paper, we used SimCLR as our main baseline, since it has superior performance on ImageNet, and we apply the changes proposed in GIM on top of SimCLR as our local learning baseline. In our experiments, we find that simply applying GIM on SimCLR results in a significant loss in performance and in the next section we will explain our techniques to bridge the performance gap.
4 LoCo: Local Contrastive Representation Learning
In this section, we will introduce our approach to close the gap between local contrastive learning and state-of-the-art end-to-end learning.
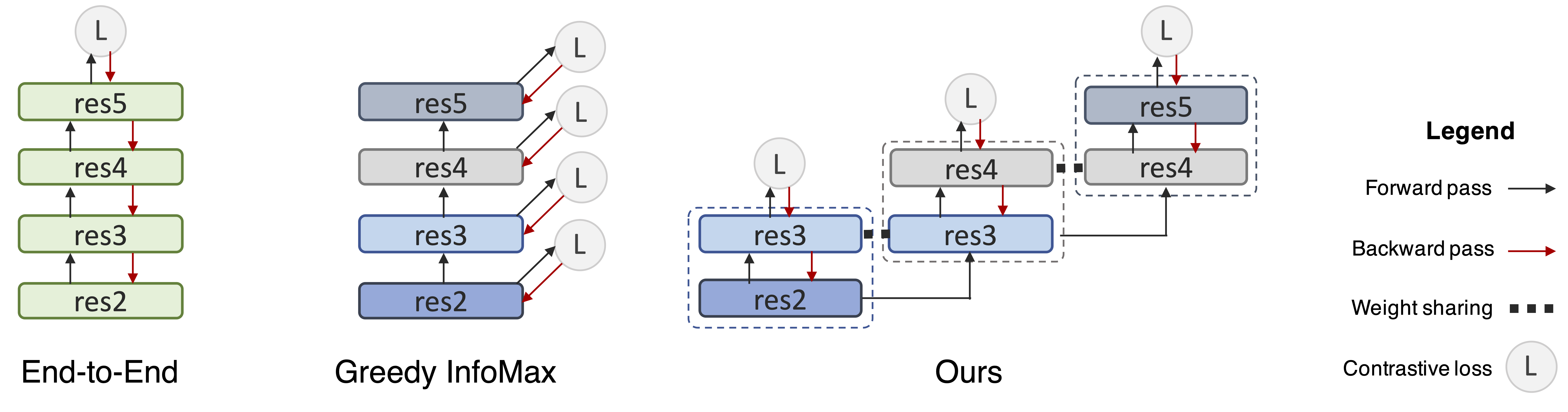
In the left part of Fig. 1, we show a regular end-to-end network using backpropagation, where each rectangle denotes a downsample stage. In ResNet-50, they are conv1+res2, res3, res4, res5. In the middle we show GIM Löwe et al. (2019), where an InfoNCE loss is added at the end of each local stage, and gradients do not flow back from upper stages to lower stages. Our experimental results will show that such practice results in much worse performance on large-scale datasets such as ImageNet. We hypothesize that it may be due to a lack of feedback from upper layers and a lack of depth in terms of the decoders of lower layers, as they are trying to greedily solve the classification problem. Towards fixing these two potential problems, on the right hand side of Fig. 1 we show our design: we group two stages into a unit, and each middle stage is simultaneously shared by two units. Next, we will go into details explaining our reasonings behind these design choices.
4.1 Bridging the Gap between Gradient Isolation Blocks
First, in GIM, the feedback from high-level features is absent. When the difficulty of the contrastive learning task increases (e.g., learning on a large-scale dataset such as ImageNet), the quality of intermediate representations from lower layers will largely affect the final performance of upper layers. However, such demand cannot be realized because lower layers are unaware of what kind of representations are required from above.
To overcome this issue, we hypothesize that it is essential to build a “bridge” between a lower stage and its upper stage so that it can receive feedback that would otherwise be lost. As shown in Fig. 1, instead of cutting the encoder into several non-overlapping parts, we can overlap the adjacent local stages. Each stage now essentially performs a “look-ahead” when performing local gradient descent. By chaining these overlapped blocks together, it is now possible to send feedback from the very top.
It is worth noting that, our method does not change the forward pass, even though res3 and res4 appear twice in Fig. 1, they receive the same inputs (from res2 and res3, respectively). Therefore the forward pass only needs to be done once in these stages, and only the backward pass is doubled.
4.2 Deeper Decoder
Second, we hypothesize that the receptive field of early stages in the encoder might be too small to effectively solve the contrastive learning problem. As the same InfoNCE function is applied to all local learning blocks (both early and late stages), it is difficult for the decoder to use intermediate representation from the early stages to successful classify the positive sample, because of the limitation of their receptive fields. For example, in the first stage, we need to perform a global average pooling on the entire feature map with a spatial dimension of before we send it to the decoder for classification.
In Section 5, we empirically verify our hypothesis by showing that adding convolutional layers into the decoder to enlarge the receptive field is essential for local algorithms. However, this change does not show any difference in the end-to-end version with a single loss, since the receptive field of the final stage is already large enough. Importantly, by having an overlapped stage shared between local units, we effectively make decoders deeper without introducing extra cost in the forward pass, simultaneously solving both issues described in this section.
5 Experiments
In this section, we conduct experiments to test the hypotheses we made in Section 4 and verify our design choices. Following previous works Zhang et al. (2016); van den Oord et al. (2018); Bachman et al. (2019); Kolesnikov et al. (2019); He et al. (2019a), we first evaluate the quality of the learned representation using ImageNet Deng et al. (2009), followed by results on MS-COCO Lin et al. (2014) and Cityscapes Cordts et al. (2016). We use SimCLR Chen et al. (2020a) and GIM Löwe et al. (2019) as our main baselines, and consider both ResNet-50 He et al. (2016) and ShuffleNet v2-50 Ma et al. (2018) backbone architectures as the encoder network.
5.1 ImageNet-1K
Implementation details:
Unless otherwise specified, we train with a batch size of 4096 using the LARS optimizer You et al. (2017). We train models 800 epochs to show that LoCo can perform well on very long training schedules and match state-of-the-art performance; we use a learning rate of 4.8 with a cosine decay schedule without restart Loshchilov and Hutter (2016); linear warm-up is used for the first 10 epochs. Standard data augmentations such as random cropping, random color distortion, and random Gaussian blurring are used. For local learning algorithms (i.e., GIM and LoCo), 2-layer MLPs with global average pooling are used to project the intermediate features into a 128-dim latent space, unless otherwise specified in ablation studies. Following Zhang et al. (2016); van den Oord et al. (2018); Bachman et al. (2019); Kolesnikov et al. (2019); He et al. (2019a), we evaluate the quality of the learned representation by freezing the encoder and training a linear classifier on top of the trained encoders. SGD without momentum is used as the optimizer for 100 training epochs with a learning rate of 30 and decayed by a factor of 10 at epoch 30, 60 and 90, the same procedure done in He et al. (2019a).
Main results:
As shown in Table 1, SimCLR achieves favorable results compared to other previous contrastive learning methods. For instance, CPC van den Oord et al. (2018), the contrastive learning algorithm which Greedy InfoMax (GIM) was originally based on, performs much worse. By applying GIM on top of SimCLR, we see a significant drop of 5% on the top 1 accuracy. Our method clearly outperforms GIM by a large margin, and is even slightly better than the end-to-end SimCLR baseline, possibly caused by the fact that better representations are obtained via multiple training losses applied at different local decoders.
| Method | Architecture | Acc. | Local |
|---|---|---|---|
| Local Agg. | ResNet-50 | 60.2 | |
| MoCo | ResNet-50 | 60.6 | |
| PIRL | ResNet-50 | 63.6 | |
| CPC v2 | ResNet-50 | 63.8 | |
| SimCLR* | ResNet-50 | 69.3 | |
| SimCLR | ResNet-50 | 69.8 | |
| GIM | ResNet-50 | 64.7 | ✓ |
| LoCo (Ours) | ResNet-50 | 69.5 | ✓ |
| SimCLR | ShuffleNet v2-50 | 69.1 | |
| GIM | ShuffleNet v2-50 | 63.5 | ✓ |
| LoCo (Ours) | ShuffleNet v2-50 | 69.3 | ✓ |
| Method | Arch | COCO | Cityscapes | ||
|---|---|---|---|---|---|
| AP | AP | AP | AP | ||
| Supervised | R-50 | 33.9 | 31.3 | 33.2 | 27.1 |
| Backbone weights with 100 Epochs | |||||
| SimCLR | R-50 | 32.2 | 29.9 | 33.2 | 28.6 |
| GIM | R-50 | 27.7 (-4.5) | 25.7 (-4.2) | 30.0 (-3.2) | 24.6 (-4.0) |
| Ours | R-50 | 32.6 (+0.4) | 30.1 (+0.2) | 33.2 (+0.0) | 28.4 (-0.2) |
| SimCLR | Sh-50 | 32.5 | 30.1 | 33.3 | 28.0 |
| GIM | Sh-50 | 27.3 (-5.2) | 25.4 (-4.7) | 29.1 (-4.2) | 23.9 (-4.1) |
| Ours | Sh-50 | 31.8 (-0.7) | 29.4 (-0.7) | 33.1 (-0.2) | 27.7 (-0.3) |
| Backbone weights with 800 Epochs | |||||
| SimCLR | R-50 | 34.8 | 32.2 | 34.8 | 30.1 |
| GIM | R-50 | 29.3 (-5.5) | 27.0 (-5.2) | 30.7 (-4.1) | 26.0 (-4.1) |
| Ours | R-50 | 34.5 (-0.3) | 32.0 (-0.2) | 34.2 (-0.6) | 29.5 (-0.6) |
| SimCLR | Sh-50 | 33.4 | 30.9 | 33.9 | 28.7 |
| GIM | Sh-50 | 28.9 (-4.5) | 26.9 (-4.0) | 29.6 (-4.3) | 23.9 (-4.8) |
| Ours | Sh-50 | 33.6 (+0.2) | 31.2 (+0.3) | 33.0 (-0.9) | 28.1 (-0.6) |
5.2 Performance on Downstream Tasks
In order to further verify the quality and generalizability of the learned representations, we use the trained encoder from previous section as pre-trained models to perform downstream tasks, We use Mask R-CNN He et al. (2017) on Cityscapes Cordts et al. (2016) and COCO Lin et al. (2014) to evaluate object detection and instance segmentation performance. Unlike what has been done in MoCo He et al. (2019a), where the whole network is finetuned on downstream task, here we freeze the pretrained backbone network, so that we better distinguish the differences in quality of different unsupervised learning methods.
Implementation details:
To mitigate the distribution gap between features from the supervised pre-training model and contrastive learning model, and reuse the same hyperparameters that are selected for the supervised pre-training model He et al. (2019a), we add SyncBN Peng et al. (2018) after all newly added layers in FPN and bbox/mask heads. The two-layer MLP box head is replaced with a 4conv-1fc box head to better leverage SyncBN Wu and He (2018). We conduct the downstream task experiments using mmdetection Chen et al. (2019). Following He et al. (2019a), we use the same hyperparameters as the ImageNet supervised counterpart for all experiments, with (12 epochs) schedule for COCO and 64 epochs for Cityscapes, respectively. Besides SimCLR and GIM, we provide one more baseline using weights pretrained on ImageNet via supervised learning provided by PyTorch111https://download.pytorch.org/models/resnet50-19c8e357.pth for reference.
Results:
From the Table 2 we can clearly see that the conclusion is consistent on downstream tasks. Better accuracy on ImageNet linear evaluation also translates to better instance segmentation quality on both COCO and Cityscapes. LoCo not only closes the gap with end-to-end baselines on object classification in the training domain but also on downstream tasks in new domains.
Surprisingly, even though SimCLR and LoCo cannot exactly match “Supervised” on ImageNet, they are 1 – 2 points AP better than “Supervised” on downstream tasks. This shows unsupervised representation learning can learn more generalizable features that are more transferable to new domains.
| Pretrain | COCO-10K | COCO-1K | ||
|---|---|---|---|---|
| Method | AP | AP | AP | AP |
| Random Init | 23.5 | 22.0 | 2.5 | 2.5 |
| Supervised | 26.0 | 23.8 | 10.4 | 10.1 |
| Pretrained weights with 100 Epochs | ||||
| SimCLR | 25.6 | 23.9 | 11.3 | 11.4 |
| GIM | 22.6 (-3.0) | 20.8 (-3.1) | 9.7 (-1.6) | 9.6 (-1.8) |
| Ours | 26.1 (+0.3) | 24.2 (+0.5) | 11.7 (+0.4) | 11.8 (+0.4) |
| Pretrained weights with 800 Epochs | ||||
| SimCLR | 27.2 | 25.2 | 13.9 | 14.1 |
| GIM | 24.4 (-2.8) | 22.4 (-2.8) | 11.5 (-2.4) | 11.7 (-2.4) |
| Ours | 27.8 (+0.6) | 25.6 (+0.4) | 13.9 (+0.0) | 13.8 (-0.3) |
5.3 Downstream Tasks with Limited Labeled Data
With the power of unsupervised representation learning, one can learn a deep model with much less amount of labeled data on downstream tasks. Following He et al. (2019b), we randomly sample 10k and 1k COCO images for training, namely COCO-10K and COCO-1K. These are 10% and 1% of the full COCO train2017 set. We report AP on the official val2017 set. Besides SimCLR and GIM, we also provide two baselines for reference: “Supervised” as mentioned in previous subsection, and “Random Init” does not use any pretrained weight but just uses random initialization for all layers and trains from scratch.
Hyperparameters are kept the same as He et al. (2019b) with multi-scale training except for adjusted learning rate and decay schedules. We train models for 60k iterations (96 epochs) on COCO-10K and 15k iterations (240 epochs) on COCO-1K with a batch size of 16. All models use ResNet-50 as the backbone and are finetuned with SyncBN Peng et al. (2018), conv1 and res2 are frozen except “Random Init" entry. We make 5 random splits for both COCO-10K/1K and run all entries on these 5 splits and take the average. The results are very stable and the variance is very small ().
Results:
Experimental results are shown in Table 3. Random initialization is significantly worse than other models that are pretrained on ImageNet, in agreement with the results reported by He et al. (2019b). With weights pretrained for 100 epochs, both SimCLR and LoCo get sometimes better performance compared to supervised pre-training, especially toward the regime of limited labels (i.e., COCO-1K). This shows that the unsupervised features are more general as they do not aim to solve the ImageNet classification problem. Again, GIM does not perform well and cannot match the randomly initialized baseline. Since we do not finetune early stages, this suggests that GIM does not learn generalizable features in its early stages. We conclude that our proposed LoCo algorithm is able to learn generalizable features for downstream tasks, and is especially beneficial when limited labeled data are available.
Similar to the previous subsection, we run pretraining longer until 800 epochs, and observe noticeable improvements on both tasks and datasets. This results seem different from the one reported in Chen et al. (2020b) that longer iterations help improve the ImageNet accuracy but do not improve downstream VOC detection performance. Using 800 epoch pretraining, both LoCo and SimCLR can outperform the supervised baseline by 2 points AP on COCO-10K and 4 points AP on COCO-1K.
5.4 Influence of the Decoder Depth
In this section, we study the influence of the decoder depth. First, we investigate the effectiveness of the convolutional layers we add in the decoder. The results are shown in Table 4. As we can see from the “1 conv block without local and sharing property” entry in the table, adding one more residual convolution block at the end of the encoder, i.e. the beginning of the decoder, in the original SimCLR does not help. One possible reason is that the receptive field is large enough at the very end of the encoder. However, adding one convolution block with downsampling before the global average pooling operation in the decoder will significantly improve the performance of local contrastive learning. We argue that such a convolution block will enlarge the receptive field as well as the capacity of the local decoders and lead to better representation learning even with gradient isolation. If the added convolution block has no downsampling factor (denoted as “w/o ds”), the improvement is not be as significant.
We also try adding more convolution layers in the decoder, including adding two convolution blocks (denoted as “2 conv blocks”), adding one stage to make the decoder as deep as the next residual stage of the encoder (denoted as “one stage”), as well as adding layers to make each decoder as deep as the full Res-50 encoder (denoted as “full network”). The results of these entries show that adding more convolution layers helps, but the improvement will eventually diminish and these entries achieve the same performance as SimCLR.
Lastly, we show that by adding two more layers in the MLP decoders, i.e. four layers in total, we can observe the same amount of performance boost on all of methods, as shown in the 4th to 6th row of Table 4. However, increasing MLP decoder depth cannot help us bridge the gap between local and end-to-end contrastive learning.
To reduce the overhead we introduce in the decoder, we decide to add one residual convolution block only and keep the MLP depth to 2, as was done the original SimCLR. It is also worth noting that by sharing one stage of the encoder, our method can already closely match SimCLR without deeper decoders, as shown in the third row of Table 4.
| Extra Layers before MLP Decoder | Local | Sharing | Acc. |
|---|---|---|---|
| None | 65.7 | ||
| None | ✓ | 60.9 | |
| 1 conv block | 65.6 | ||
| 1 conv block (w/o ds) | ✓ | 63.6 | |
| 1 conv block | ✓ | 65.1 | |
| 2 conv blocks | ✓ | 65.8 | |
| 1 stage | ✓ | 65.8 | |
| full network | ✓ | 65.8 | |
| 2-layer MLP | 67.1 | ||
| 2-layer MLP | ✓ | 62.3 | |
| Ours | ✓ | ✓ | 66.2 |
| Ours + 2-layer MLP | ✓ | ✓ | 67.5 |
| Sharing description | Acc. |
|---|---|
| No sharing | 65.1 |
| Upper layer grad only | 65.3 |
| L2 penalty (1e-4) | 65.5 |
| L2 penalty (1e-3) | 66.0 |
| L2 penalty (1e-2) | 65.9 |
| Sharing 1 block | 64.8 |
| Sharing 2 blocks | 65.3 |
| Sharing 1 stage | 66.2 |
5.5 Influence of the Sharing Strategy
As we argued in Sec. 4.1 that local contrastive learning may suffer from gradient isolation, it is important to verify this situation and know how to build a feedback mechanism properly. In Table 5, we explore several sharing strategies to show their impact of the performance. All entries are equipped with 1 residual convolution block + 2-layer MLP decoders.
We would like to study what kind of sharing can build implicit feedback. In LoCo the shared stage between two local learning modules is updated by gradients associated with losses from both lower and upper local learning modules. Can implicit feedback be achieved by another way? To answer this question, we try to discard part of the gradients of a block shared in both local and upper local learning modules. Only the gradients calculated from the loss associated with the upper module will be kept to update the weights. This control is denoted as “Upper layer grad only” in Table 5 and the result indicates that although the performance is slightly improved compared to not sharing any encoder blocks, it is worse than taking gradients from both sides.
We also investigate soft sharing, i.e. weights are not directly shared in different local learning modules but are instead softly tied using L2 penalty on the differences. For each layer in the shared stage, e.g., layers in res3, the weights are identical in different local learning modules upon initialization, and they will diverge as the training progress goes on. We add an L2 penalty on the difference of the weights in each pair of local learning modules, similar to L2 regularization on weights during neural network training. We try three different coefficients from 1e-2 to 1e-4 to control the strength of soft sharing. The results in Table 5 show that soft sharing also brings improvements but it is slightly worse than hard sharing. Note that with this strategy the forward computation cannot be shared and the computation cost is increased. Thus we believe that soft sharing is not an ideal way to achieve good performance.
Finally, we test whether sharing can be done with fewer residual convolution blocks between local learning modules rather than a whole stage, in other words, we vary the size of the local learning modules to observe any differences. We try to make each module contain only one stage plus a few residual blocks at the beginning of the next stage instead of two entire stages. Therefore, only the blocks at the beginning of stages are shared between different modules. This can be seen as a smooth transition between GIM and LoCo. We try only sharing the first block or first two blocks of each stage, leading to “Sharing 1 block” and “Sharing 2 blocks” entries in Table 5. The results show that sharing fewer blocks of each stage will not improve performance and sharing only 1 block will even hurt.
5.6 Memory Saving
Although local learning saves GPU memory, we find that the original ResNet-50 architecture prevents LoCo to further benefit from local learning, since ResNet-50 was designed with balanced computation cost at each stage and memory footprint was not taken into consideration. In ResNet, when performing downsampling operations at the beginning of each stage, the spatial dimension is reduced by but the number of channels only doubles, therefore the memory usage of the lower stage will be twice as much as the upper stage. Such design choice makes conv1 and res2 almost occupy 50% of the network memory footprint. When using ResNet-50, the memory saving ratio of GIM is compared to the original, where the memory saving ratio is defined as the reciprocal of peak memory usage between two models. LoCo can achieve memory saving ratio since it needs to store one extra stage.
We also show that by properly designing the network architecture, we can make training benefit more from local learning. We change the 4-stage ResNet to a 6-stage variant with a more progressive downsampling mechanism. In particular, each stage has 3 residual blocks, leading to a Progressive ResNet-50 (PResNet-50). Table 6 compares memory footprint and computation of each stage for PResNet-56 and ResNet-50 in detail. The number of base channels for each stage are 56, 96, 144, 256, 512, 1024, respectively. After conv1 and pool1, we gradually downsample the feature map resolution from 56x56 to 36x36, 24x24, 16x16, 12x12, 8x8 at each stage with bilinear interpolation instead of strided convolution He et al. (2016). Grouped convolution Krizhevsky et al. (2012) with 2, 16, 128 groups is used in the last three stages respectively to reduce the computation cost. The difference between PResNet-56 and ResNet-50 and block structures are illustrated in appendix.
By simply making this modification without other new techniques He et al. (2019c); Hu et al. (2018); Li et al. (2019), we can get a network that matches the ResNet-50 performance with similar computation costs. More importantly, it has balanced memory footprint at each stage. As shown in Table 7, SimCLR using PResNet-50 gets 66.8% accuracy, slightly better compared to the ResNet-50 encoder. Using PResNet-50, our method performs on par with SimCLR while still achieving remarkable memory savings of 2.76 . By contrast, GIM now has an even larger gap (14 points behind SimCLR) compared to before with ResNet-50, possibly due to the receptive field issue we mentioned in Sec. 4.2.
| Stage | PResNet-50 | ResNet-50 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
||||||||
| res2 | 15.46 | 13.50 | 43.64 | 19.39 | |||||||
| res3 | 10.96 | 14.63 | 29.09 | 25.09 | |||||||
| res4 | 19.48 | 14.77 | 21.82 | 35.80 | |||||||
| res5 | 17.31 | 16.62 | 5.45 | 19.73 | |||||||
| res6 | 19.48 | 20.45 | - | - | |||||||
| res7 | 17.31 | 20.04 | - | - | |||||||
| FLOPs | 4.16G | 4.14G | |||||||||
| Method | Acc. | Memory Saving Ratio |
|---|---|---|
| SimCLR | 66.8 | 1 |
| GIM | 52.6 | 4.56 |
| LoCo | 66.6 | 2.76 |
6 Conclusion
We have presented LoCo, a local learning algorithm for unsupervised contrastive learning. We show that by introducing implicit gradient feedback between the gradient isolation blocks and properly deepening the decoders, we can largely close the gap between local contrastive learning and state-of-the-art end-to-end contrastive learning frameworks. Experiments on ImageNet and downstream tasks show that LoCo can learn good visual representations for both object recognition and instance segmentation just like end-to-end approaches can. Meanwhile, it can benefit from nice properties of local learning, such as lower peak memory footprint and faster model parallel training.
References
- Synaptic plasticity: taming the beast. Nature neuroscience 3 (11), pp. 1178–1183. Cited by: §2.
- Learning representations by maximizing mutual information across views. In Advances in Neural Information Processing Systems, NeurIPS, Cited by: §5.1, §5.
- Greedy layerwise learning can scale to imagenet. arXiv preprint arXiv:1812.11446. Cited by: §2, §2.
- Greedy layer-wise training of deep networks. In Advances in Neural Information Processing Systems, NIPS, B. Schölkopf, J. C. Platt, and T. Hofmann (Eds.), Cited by: §2.
- Towards biologically plausible deep learning. CoRR abs/1502.04156. Cited by: §1, §2.
- How auto-encoders could provide credit assignment in deep networks via target propagation. CoRR abs/1407.7906. Cited by: §2.
- Theory for the development of neuron selectivity: orientation specificity and binocular interaction in visual cortex. Journal of Neuroscience 2 (1), pp. 32–48. Cited by: §2.
- Spike timing–dependent plasticity: a hebbian learning rule. Annu. Rev. Neurosci. 31, pp. 25–46. Cited by: §1, §2.
- Deep clustering for unsupervised learning of visual features. In 15th European Conference on Computer Vision, ECCV, V. Ferrari, M. Hebert, C. Sminchisescu, and Y. Weiss (Eds.), Cited by: §2.
- MMDetection: open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155. Cited by: §5.2.
- Training deep nets with sublinear memory cost. CoRR abs/1604.06174. Cited by: §2.
- A simple framework for contrastive learning of visual representations. CoRR abs/2002.05709. Cited by: §1, §1, §1, §2, §3.1, §5.
- Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297. Cited by: §5.3.
- An analysis of single-layer networks in unsupervised feature learning. In 14th International Conference on Artificial Intelligence and Statistics, AISTATS, Cited by: §3.2.
- The cityscapes dataset for semantic urban scene understanding. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Cited by: §1, §5.2, §5.
- Imagenet: a large-scale hierarchical image database. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Cited by: §1, §1, §5.
- Unsupervised visual representation learning by context prediction. In IEEE International Conference on Computer Vision, ICCV, Cited by: §2.
- Unsupervised representation learning by predicting image rotations. In 6th International Conference on Learning Representations, ICLR, Cited by: §2.
- The reversible residual network: backpropagation without storing activations. In Advances in Neural Information Processing Systems, NIPS, Cited by: §2.
- Scaling and benchmarking self-supervised visual representation learning. In 2019 IEEE/CVF International Conference on Computer Vision, ICCV, Cited by: §2.
- Memory-efficient backpropagation through time. In Advances in Neural Information Processing Systems, NIPS, Cited by: §2.
- Momentum contrast for unsupervised visual representation learning. CoRR abs/1911.05722. Cited by: §1, §2, §5.1, §5.2, §5.2, §5.
- Rethinking imagenet pre-training. In IEEE International Conference on Computer Vision, ICCV, Cited by: §5.3, §5.3, §5.3.
- Mask R-CNN. In IEEE International Conference on Computer Vision, ICCV, Cited by: §5.2.
- Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Cited by: §1, §5.6, §5.
- Bag of tricks for image classification with convolutional neural networks. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Cited by: §5.6.
- The organization of behavior: a neuropsychological theory. J. Wiley; Chapman & Hall. Cited by: §2.
- A fast learning algorithm for deep belief nets. Neural Computation 18 (7), pp. 1527–1554. Cited by: §2.
- A practical guide to training restricted boltzmann machines. In Neural networks: Tricks of the trade, pp. 599–619. Cited by: §2.
- Squeeze-and-excitation networks. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Cited by: §5.6.
- Gpipe: efficient training of giant neural networks using pipeline parallelism. In Advances in Neural Information Processing Systems, NeurIPS, pp. 103–112. Cited by: §2.
- Decoupled neural interfaces using synthetic gradients. In 34th International Conference on Machine Learning, ICML, Cited by: §2.
- Revisiting self-supervised visual representation learning. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Cited by: §5.1, §5.
- ImageNet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems, NIPS, Cited by: §2, §2, §5.6.
- One weird trick for parallelizing convolutional neural networks. CoRR abs/1404.5997. Cited by: §2.
- Selective kernel networks. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Cited by: §5.6.
- Microsoft COCO: common objects in context. In 13th European Conference on Computer Vision, ECCV, D. J. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars (Eds.), Cited by: §1, §5.2, §5.
- Sgdr: stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983. Cited by: §5.1.
- Putting an end to end-to-end: gradient-isolated learning of representations. In Advances in Neural Information Processing Systems, NeurIPS, Cited by: LoCo: Local Contrastive Representation Learning, §1, §1, §1, §2, §2, §3.2, §3, §4, §5.
- Shufflenet v2: practical guidelines for efficient cnn architecture design. In 15th European Conference on Computer Vision, ECCV, Cited by: §1, §5.
- Visualizing data using t-sne. Journal of machine learning research 9 (Nov), pp. 2579–2605. Cited by: Appendix C.
- Meta-learning update rules for unsupervised representation learning. In 7th International Conference on Learning Representations, ICLR, Cited by: §2.
- Backpropamine: training self-modifying neural networks with differentiable neuromodulated plasticity. In 7th International Conference on Learning Representations, ICLR, Cited by: §2.
- Differentiable plasticity: training plastic neural networks with backpropagation. In 35th International Conference on Machine Learning, ICML, J. G. Dy and A. Krause (Eds.), Cited by: §2.
- Self-supervised learning of pretext-invariant representations. CoRR abs/1912.01991. Cited by: §1, §2.
- PipeDream: generalized pipeline parallelism for dnn training. In 27th ACM Symposium on Operating Systems Principles, SOSP, Cited by: §1, §2.
- Direct feedback alignment provides learning in deep neural networks. In Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems, NeurIPS, D. D. Lee, M. Sugiyama, U. von Luxburg, I. Guyon, and R. Garnett (Eds.), Cited by: §2.
- Unsupervised learning of visual representations by solving jigsaw puzzles. In 14th European Conference on Computer Vision - ECCV, B. Leibe, J. Matas, N. Sebe, and M. Welling (Eds.), Cited by: §2.
- Representation learning by learning to count. In IEEE International Conference on Computer Vision, ICCV, Cited by: §2.
- Simplified neuron model as a principal component analyzer. Journal of mathematical biology 15 (3), pp. 267–273. Cited by: §2.
- Megdet: a large mini-batch object detector. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Cited by: §5.2, §5.3.
- Brain-score: which artificial neural network for object recognition is most brain-like?. bioRxiv 10.1101/407007. Cited by: §2.
- Measuring the effects of data parallelismon neural network training. Journal of Machine Learning Research 20. Cited by: §2.
- Information processing in dynamical systems: foundations of harmony theory. Technical report Colorado Univ at Boulder Dept of Computer Science. Cited by: §2.
- Contrastive multiview coding. CoRR abs/1906.05849. Cited by: §1, §2.
- Representation learning with contrastive predictive coding. CoRR abs/1807.03748. Cited by: §2, §3.1, §3.2, §3, §5.1, §5.1, §5.
- Group normalization. In 15th European Conference on Computer Vision, ECCV, Cited by: §5.2.
- Learning to remember from a multi-task teacher. CoRR abs/1910.04650. Cited by: §2.
- Large batch training of convolutional networks. arXiv preprint arXiv:1708.03888. Cited by: §5.1.
- Colorful image colorization. In 14th European Conference on Computer Vision, ECCV, B. Leibe, J. Matas, N. Sebe, and M. Welling (Eds.), Cited by: §2, §5.1, §5.
- Unsupervised neural network models of the ventral visual stream. bioRxiv 10.1101/2020.06.16.155556. Cited by: §2.
- Local aggregation for unsupervised learning of visual embeddings. In IEEE/CVF International Conference on Computer Vision, ICCV, Cited by: §2.
Appendix A Training Curves
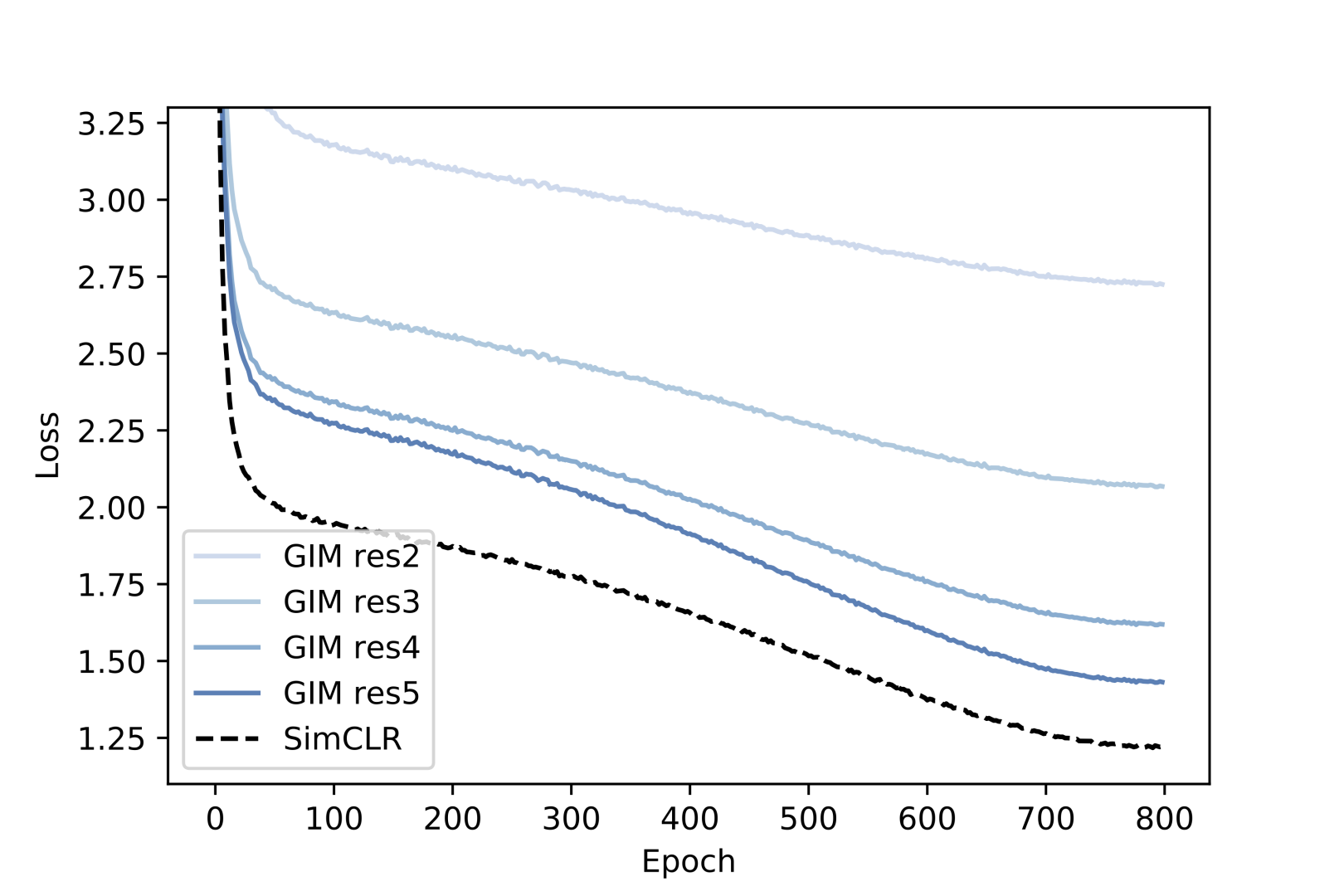
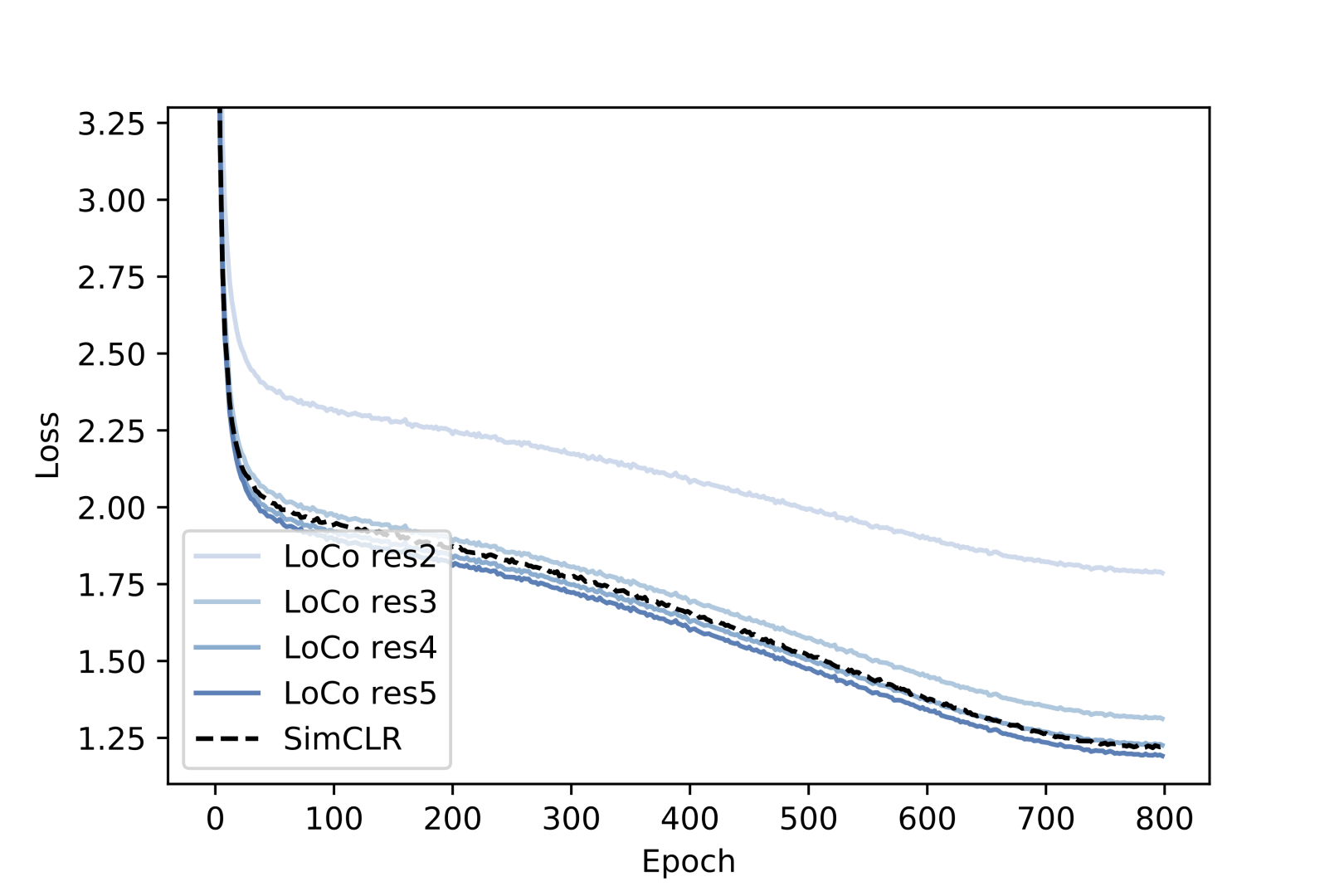
We provide training loss curves of SimCLR, GIM and LoCo for a better understanding of the performance gap between them. Contrastive losses computed using outputs from the full ResNet-50 encoder are shown in Fig. 2. For GIM and LoCo, losses from other decoders, including res2, res3, res4, are also provided. As we can see in Fig. 2, the losses of different decoders in LoCo closely match the loss of the decoder in SimCLR during training, with the exception of res2, while for GIM this is not the case.
 |
 |
Appendix B Architecture of Progressive ResNet-50
In this section we show the block structure of each stage in Progressive ResNet-50 in Table 8. The block structure of ResNet-50 is also shown here for reference. We downsample the feature map size progressively using bilinear interpolation, and use basic blocks to reduce the memory footprint of earlier stages, and group convolution to reduce the computation cost of later stages to get a model with more balanced computation and memory footprint at each stage. We use this model to show the great potential of LoCo in terms of both memory saving and computation for model parallelism. As it is designed to have 15~20 memory footprint and computation cost per stage, the peak memory usage will be significantly reduced in local learning, and no worker that handles a stage of the encoder will become a computation bottleneck in model parallelism.
| layer | PResNet-50 | ResNet-50 | ||||
| output size | block structure | output size | block structure | |||
| conv1 | 112112 | 7x7, 32, stride 2 | 112112 | 77, 64, stride 2 | ||
| res2_x | 5656 | 33 max pool, stride 2 | 5656 | 33 max pool, stride 2 | ||
| 3 | 3 | |||||
| res3_x | 3636 | 3 | 2828 | 4 | ||
| res4_x | 2424 | 3 | 1414 | 6 | ||
| res5_x | 1616 |
|
77 | 3 | ||
| res6_x | 1212 |
|
- | - | ||
| res7_x | 88 |
|
- | - | ||
| 11 | average pool, 1000-d fc | 11 | average pool, 1000-d fc | |||
Appendix C Representation visualization
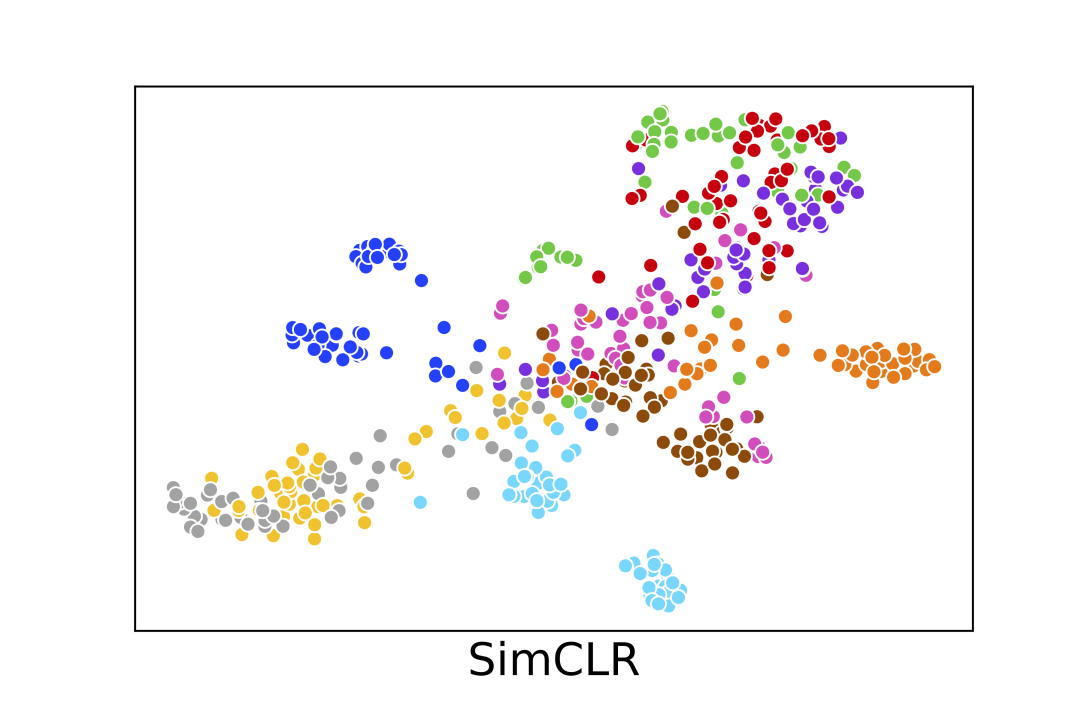
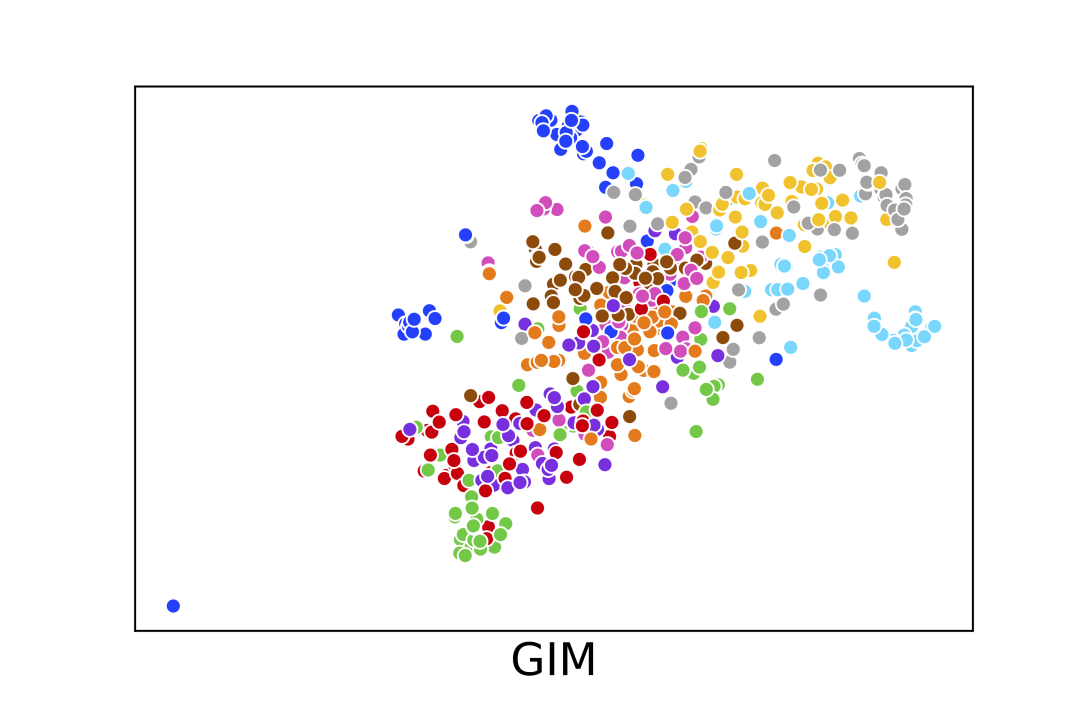
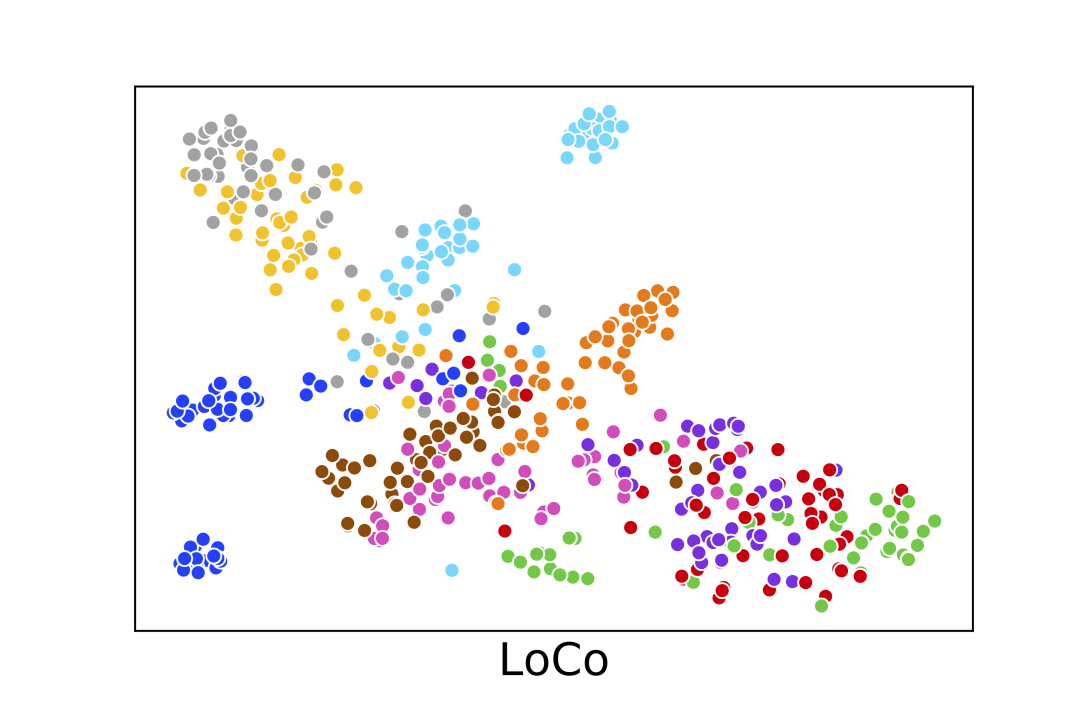
In this section we show some visualization results of the learned representation of SimCLR, GIM and LoCo. We subsample images belonging to the first 10 classes of ImageNet-1K from the validation set (500 images in total) and use t-SNE Maaten and Hinton (2008) to visualize the 4096-d vector representation from the PResNet-50 encoder. The results are shown in Fig 3. We can see LoCo learns image embedding vectors that can form more compact clusters compared to GIM.
 |
 |
 |
Appendix D Qualitative results for downstream tasks
Last, we show qualitative results of detection and instance segmentation tasks on COCO in Fig. 4.
